Le mercredi 3 avril a eu lieu l’AWS Summit Paris, événement organisé par AWS pour permettre à la communauté du cloud computing (utilisateurs et partenaires), de se connecter, collaborer … et accessoirement en savoir plus sur AWS et ses services.
Les 3 grandes thématiques à l’honneur lors de cet événement étaient (je vais sûrement vous surprendre !) le cloud, la data et … l’Intelligence Artificielle (IA) !
Pour mon plus grand plaisir, et le vôtre j’espère, j’ai donc passé la journée à naviguer de conférences en espaces démo pour vous retranscrire dans cet article en deux parties une synthèse des recommandations clés relatives à la sécurisation des cas d’usage IA. Je vais commencer cette première partie par une synthèse des cas d’usage IA et enjeux sécurité mis en avant par les clients AWS lors de la key note d’ouverture, et j’enchaînerais avec un résumé d’une conférence co-animée par AWS et APICIL sur les bonnes pratiques de gouvernance de la donnée, prérequis indispensable selon moi à une sécurisation efficace de l’IA. Dans la seconde partie de cet article, nous aborderons deux autres éléments majeurs : tout d’abord une présentation pas à pas d’une démarche d’analyse de risque sécurité d’une application d’IA Gen puis une vue d’ensemble des principes à mettre en œuvre pour développer des IA Gen “responsables” (cette 2e partie s’appuie sur le contenu de deux conférences animées par AWS).
Pour commencer, rapide historique et état des lieux des enjeux IA des clients
Tout évènement d’ampleur qui se respecte commence par une key note d’ouverture, et l’AWS Summit n’a pas dérogé à la tradition. AWS a démarré sa présentation en brossant un rapide panorama des révolutions techniques, de la révolution industrielle des années 1800 jusqu’à celle de 1983 marquée par l’arrivée de l’internet (TCP/IP et web, cloud) en passant par la révolution numérique amorcée en 1947 avec l’arrivée du transistor et de l’amplificateur opérationnel. Tous ces bonds technologiques nous ont amenés au tournant des années 2020 à la nouvelle révolution en cours, celle de l’IA. Cette révolution porte un objectif bien spécifique : les activités informatiques ne visent plus seulement à accroître notre efficacité mais désormais à automatiser des tâches complexes jusqu’à présent uniquement réalisables par la pensée et le raisonnement humain.
Une fois ce rappel historique posé, AWS a présenté sa stratégie d’accompagnement client, structurée autour de trois axes : liberté de choix des solutions, protection de la confidentialité et gestion des coûts.
Une stratégie à décliner aussi du côté client. A titre d’exemples, AWS a laissé la lumière à plusieurs clients, qui ont chacun présenté leurs projets de data et d’IA, les enjeux auxquels ils font face et/ou les solutions pour les traiter.
L’entreprise Mistral AI a ouvert le bal, pour présenter ses deux principaux enjeux en termes d’IA, à savoir :
- Gérer la complexité croissante des applications qui utilisent les LLM,1
- Construire des infrastructures ultra performantes capables de répondre à des besoins de latence applicative extrêmement faibles.
Air Liquide a rebondi sur le thème de la performance en présentant les composants clés de ses infrastructures « data » et « IA », à savoir un mix de serverless, services managés et conteneurs, qui lui permet d’assurer notamment :
- La collecte journalière de 3,5 milliards de données produites par ses 600 usines,
- Le pilotage et l’utilisation des objets connectés intégrés dans les chaînes d’approvisionnement en gaz de ses clients,
- La mise en production et la maintenance d’environ 500 projets d’IA Gen.
(où quand les chiffres prennent des dimensions stratosphériques 😉)
Air Liquide a ensuite fait un focus sur les quatre grands enjeux auxquels elle fait face pour assurer le succès de ses projets d’IA Gen :
- Des enjeux techniques, et notamment de performance, comme rappelé juste avant,
- Des enjeux de transparence des traitements,
- Des enjeux de fiabilité des résultats (dans un contexte d’attaques malveillantes ou d’erreurs d’entraînement),
- Des enjeux de maîtrise des coûts financiers et énergétiques.
Pour arbitrer les mesures techniques, fonctionnelles et sécurité à mettre en place pour traiter ces enjeux, Air Liquide a construit une stratégie d’IA alimentée par les résultats d’analyses des risques industriels, et dont l’objectif est de garantir le respect de 3 fondamentaux : la prudence, l’éthique et la saisie des opportunités.
Cette approche lui a permis de mener un ensemble de tests et prototypes applicatifs data et IA et de valider le lancement d’environ 500 projets visant à proposer de nouveaux services pour les Métiers et clients de l’entreprise.
De son côté, Hugging Face a présenté la façon dont elle utilise les ressources d’IA mises à disposition par OpenAI tout en veillant à respecter ses besoins prioritaires, à savoir :
- Garantir la transparence et la sécurité de ses modèles d’IA,
- Disposer d’une capacité d’évaluer les modèles à utiliser (où comment faire le tri dans un hub mettant à disposition un demi-million de modèles),
- Assurer un passage à l’échelle (via l’utilisation de modèles plus petits, offrant une latence réduite et un ROI adapté aux cas d’usage cibles).
Enfin, TF1 a clos cette key note en expliquant comment elle a développé des systèmes d’IA pour créer et/ou automatiser les processus permettant d’améliorer l’expérience utilisateur, la productivité mais aussi sa capacité à vérifier la production de ses contenus.
Briques de sécurisation de l’IA
Comme on le voit à travers les retours d’expériences clients, l’IA met les entreprises face à un ensemble d’injonctions parfois contradictoires, a minima complexes à mener de front : assurer la performance des services, la fiabilité des résultats, la transparence des traitements et la protection des données.
Des injonctions qui rappellent furieusement … les exigences portées par la sécurité, à savoir la disponibilité, l’intégrité, la confidentialité et la traçabilité (DICT).
Alors, justement ! Quelles sont les bonnes pratiques à mettre en œuvre pour assurer une bonne gestion du DICT lors du développement des cas d’usages IA ?
Mesure A – La gouvernance de la donnée
Avant toute chose, maîtriser la gouvernance des données ! On ne le répètera jamais assez, l’IA « it’s all about data ! » Et grâce à une bonne hygiène de la gouvernance des données, il est possible d’innover plus rapidement, et de façon plus sécurisée. C’était d’ailleurs le message clé de la conférence « Gouvernez vos données et vos modèles d’intelligence artificielle », animée par Joël Farvault, référent data d’AWS, et Vincent Compagnon, Manager Plateforme Data et Plateforme RPA d’APICIL.
Par gouvernance des données, il est fait référence à l’ensemble des ressources (politiques, processus et systèmes techniques) mis en œuvre pour s’assurer de l’atteinte des trois fondamentaux suivants :
- Organiser : mettre en place les éléments permettant de trouver, accéder et partager des données fiables de la façon la plus efficiente et exhaustive possible, à travers des actions maîtrisées de « master data management » (gestion des données de référence), d’intégration et de gestion de la qualité des données.
- Protéger : assurer la sécurité des données, notamment à travers la mise en œuvre de bout en bout du principe de « least privilege » (du sourcing de la donnée jusqu’à l’implémentation des cas d’usage finaux), la mise en conformité aux règles internes, légales et réglementaires et la gestion adéquate du cycle de vie des données (de sa création à sa destruction en passant par son accès et son archivage).
- Comprendre : mener des audits et contrôles appropriés pour disposer à la fois de visibilité et d’une bonne compréhension des traitements réalisés sur les données. Ceci permet d’assurer un partage des données cohérent avec les principes des architectures techniques et fonctionnelles sous-jacentes. Cette compréhension s’obtient à travers des actions de profilage des données (pour comprendre leur utilisation), de traçabilité et la mise en place d’un catalogue des données.
Le déploiement maîtrisé et sécurisé des cas d’usage IA commence donc par une prise en compte de ces 3 fondamentaux, combinés à l’usage de services techniques adaptés. Parmi les nombreux exemples fournis par APICIL pour illustrer la mise en œuvre de cette stratégie, j’ai choisi les deux suivants :
- L’anonymisation des données (dans un objectif de mise en conformité au RGPD) : APICIL souhaitait éviter à ses référents Métier la recherche et qualification manuelles de chaque donnée stockée dans les bases de données sollicitées par ses cas d’usage IA. Noble intention ! Pour cela, APICIL a choisi de mettre en place un dispositif permettant à la brique SnowFlake de définir automatiquement la probabilité qu’une donnée soit possiblement soumise au RGPD puis de déclencher un processus de masquage si cette probabilité dépasse les seuils définis en amont avec les Métiers.
- Le profilage des données : APICIL a présenté le dispositif mis en place pour faciliter l’accès et le partage de ses données selon un modèle de « producteurs / consommateurs », et notamment le service Amazon DataZone, afin de mettre à jour, gérer et administrer ses données et méta données, aussi bien sous l’angle technique que métier (pour une vision sémantique des méta données techniques).
Pour finir, AWS et APICIL ont mis en avant les facteurs clés de succès pour mettre en place une gouvernance des données pragmatique et efficiente :
- Définir une stratégie qui prend en compte les 3 dimensions « organiser » – « protéger » – « comprendre » tout en sachant prioriser les actions à mener au sein de chaque pilier (en fonction des cas d’usage IA à déployer, du niveau de maturité de son organisation, de l’existant en termes d’architecture data, …),
- Impliquer toutes les équipes, dont les Métiers (hé oui….),
- Automatiser au maximum les processus de gouvernance des données,
- Utiliser les solutions / services les plus adaptés à son contexte (services natifs cloud et/ou solutions de fournisseurs tiers)
Nous voilà à la fin de la première partie de cet article. Nous avons identifié quelques-uns des enjeux de sécurité majeurs des projets d’IA ainsi que les principes clés d’une démarche de gouvernance de la donnée. Dans la seconde partie, je vous présenterais pas à pas une démarche d’analyse de risque sécurité d’une application d’IA Gen et les éléments indispensables pour mettre en œuvre pour créer des IA Gen “responsables”.
Deuxième partie
Dans la première partie de cet article, nous avons identifié quelques-uns des enjeux de sécurité majeurs des projets d’IA ainsi que les principes clés d’une démarche de gouvernance de la donnée. Dans cette seconde partie, je vais vous présenter pas à pas une démarche d’analyse de risque sécurité d’une application d’IA Gen ainsi que les éléments indispensables pour mettre en œuvre pour créer des IA Gen “responsables”.
Briques de sécurisation de l’IA (suite)
Mesure B – L’identification en amont des menaces
Disposer d’une bonne gouvernance de ses données est un prérequis indispensable, mais ce n’est évidemment pas suffisant. Un second élément clé dans la sécurisation de ses cas d’usage IA est l’identification et le traitement des menaces. C’était justement le sujet de la conférence « Modélisez les menaces pour mieux protéger vos applications d’IA générative ».
Dans cette conférence, Stéphanie Mbappe et Alexandre Agius, tous les deux représentants d’AWS, nous ont présentés les 4 étapes à mener pour identifier et se protéger des menaces pouvant impacter une appli d’IA Gen, à savoir identifier…
- Le périmètre à analyser,
- Les problèmes potentiels,
- Les contre-mesures,
- Les contrôles à mettre en œuvre pour s’assurer de l’efficacité des contre-mesures.
Avant de se lancer dans le cœur de la présentation, AWS a présenté le rôle de « Security Gardian » (SG), référent sécurité déployé au sein des équipes de développement d’AWS. Il intervient principalement en début et fin de projet (selon la règle du 80/20) ; et, pour le cas qui nous concerne, il est notamment chargé de mettre en œuvre la démarche d’identification des menaces détaillée dans la suite de la conférence.
Pour leur permettre de pleinement assurer leurs fonctions, AWS a mis en place un parcours de formation continue de ses SG, afin qu’ils disposent d’une bonne connaissance des principes généraux de sécurité, ainsi que des meilleures pratiques de développement sécurisé et de modélisation des menaces.
Une fois ce rôle de SG posé, nous sommes prêts à passer en revue les 4 étapes d’identification et de traitement des menaces.
Étape 1 : identifier le périmètre à analyser
Pour mener à bien l’analyse des menaces, le SG commence par collecter auprès de l’équipe de développement et des autres référents projet, toute une série d’informations, dont :
- Le diagramme d’architecture (incluant les briques de sécurité déjà prévues, comme les composants en charge de l’authentification ou les modules de révision automatisée du code source),
- La cartographie des flux de données,
- La description du contexte métier : inventaire des risques d’entreprise spécifiques aux cas d’usage et aux exigences de conformité internes / légales / règlementaires,
- Le.s modèle.s de menaces à utiliser. En l’occurrence, AWS s’appuie sur le modèle STRIDE, structuré autour de 6 « spectres » : Spoofing (usurpation d‘identité), Tampering (falsification des données), Repudiation, divulgation d’Informations et Déni de service. A noter qu’il il existe d’autres modèles, comme P.A.S.T.A (Process for Attack Simulation and Threat Analysis) ou le MITRE ATLAS™ (Adversarial Threat Landscape for Artificial-Intelligence Systems – modèle spécifique aux cas d’usage d’IA),
- Des référentiels de menaces (ex. : le top10 de l’OWASP).
Étape 2 : identifier les problèmes potentiels
Avec toutes ces informations en main, le SG peut commencer à identifier les différentes menaces pouvant impacter une appli d’IA Gen, et à décrire les étapes du scénario exploitant chacune de ces menaces. Pour cela, il décline la phrase type suivante :
« Une [menace source] à l’aide de [prérequis],
Peut [action de la menace],
Ce qui conduit à [impact de la menace],
Impactant négativement [objectifs et ressources impactées] »
Pour illustrer cette démarche, AWS a présenté le cas fictif d’une application de GenIA gérant des questions / réponses dans le domaine de la santé. Ce cas est schématisé dans l’image ci-dessous :
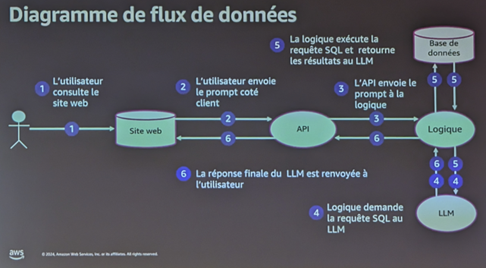
Le SG commence par identifier avec l’équipe de développement la ressource projet la plus importante et les traitements réalisés sur cette ressource (le « quoi » et le « qui »). Dans notre exemple, il a été décidé de porter l’attention sur les données stockées.
À partir de là, le SG utilise la phrase type mentionnée plus haut pour décrire les menaces pouvant impacter la ressource clé. Dans le cas de notre exemple, la première menace identifiée est décrite de la façon suivante :
« Un acteur hostile externe ayant accès à l’application publique,
Peut injecter un prompt malveillant qui écrase le prompt existant,
Ce qui conduit à la récupération de données de santé d’autres patients,
Impactant la confidentialité des données de la base de données »
Le SG vérifie ensuite avec l’équipe de développement s’il existe des failles permettant de matérialiser cette menace. Dans le cas pris en exemple, une série de tests et vérifications permet de confirmer l’existence de plusieurs failles permettant à un attaquant d’obtenir plus d’informations que ce à quoi il devrait avoir normalement accès. Ces failles sont organisées dans le scénario d’attaque suivant :

Une fois la menace identifiée, confirmée et scénarisée, le SG la documente dans un référentiel des menaces, confirme avec l’équipe projet le niveau de priorité de traitement et catégorise cette menace par rapport au modèle de menaces retenu (dans le cas du modèle STRIDE : « S » pour « spoofing / usurpation d’identité » et « I » pour « divulgation d’informations »).
Étape 3 : identifier les contre-mesures
Pour chacune des failles identifiées, le « SG » définit ensuite avec l’équipe de développement les mesures de protection à mettre en œuvre :
- « L’application accepte tous les prompts de l’utilisateur » : dans ce cas-là, il convient de définir ce qui caractérise stricto sensu un prompt acceptable pour l’utilisateur.
- « Le prompt est passé au LLM depuis la logique » : grâce aux mesures de sécurité mises en place au niveau du prompt, l’équipe de développement sait ce qui est attendu en entrée, et peut donc restreindre le LLM à des paramètres spécifiques connus et maitrisés.
- « LLM utilise le prompt pour générer une requête SQL » : pour contrer cette faille, il convient de créer des requêtes SQL prédéfinies (ou « prepared statements »).
- « Le résultat SQL est passé à l’utilisateur via la réponse LLM » : pour limiter ce risque, il est nécessaire de filtrer le retour attendu. Ceci est d’autant plus facile que, grâce à la mesure de sécurité précédente, l’équipe de développement connait exactement les sorties acceptables.
Pour finir, le SG finalise son plan de correction en vérifiant le mapping entre les mesures qui viennent d’être définies et celles définies dans les référentiels de menaces standards (ex. : le top10 de l’OWASP).
L’image ci-dessus montre la façon dans l’ensemble des informations est enregistré dans le référentiel des menaces, une fois toutes les étapes réalisées :

Étape 4 : identifier les contrôles
Pour finie, le SG identifie avec l’équipe projet les contrôles à mettre en place pour s’assurer dans le temps que les mesures de sécurité sont adaptées, …. et le restent !
Pour cela, il est possible de mettre en place :
- Des tests d’intrusion à chaque publication ou montée de version ;
- Des tests automatisés (note – pour le moment il n’existe pas de solution pour réaliser ce type de tests sur le LLM mais on peut en réaliser sur d’autres briques de l’écosystème, comme les modules d’authentification) ;
- Des étapes de revalidation pour s’assurer que le modèle de menaces utilisé comme support aux analyses de risque reste satisfaisant et répond toujours aux besoins au fil de temps ;
- Des étapes de réévaluation régulière de la complétude et pertinence des menaces initialement identifiées.
Mesure C – Être innovant ET responsable
Au chapitre précédent, nous avons vu les étapes à réaliser pour se protéger des menaces classiques affectant le DICT. Mais les IA Gen, du fait de leurs interactions avec les êtres humains, sont soumises à d’autres risques. C’est pourquoi AWS recommande d’aller au -delà de la recherche de la sécurité pour construire des applications d’IA Gen qui soient aussi “responsables”.
À ce titre, dans la conférence « Innover de manière responsable avec l’IA Gen : de la théorie à la pratique » Mohamed Walid Benabderrahmane (SA AWS) et Yasmina Fares Amado (Sustainability and Innovation Lead AWS) ont présenté une démarche de traitement des 4 principaux risques de déploiement d’une IA non-responsable.
Pour commencer, qu’est-ce qu’on entend par une IA Gen “responsable” ? AWS définit ce terme en présentant les 6 fondamentaux suivants :
- La confidentialité et la sécurité : protéger les données et modèles contre le vol et la divulgation) ;
- L’équité : considérer l’impact d’un système sur les différentes sous-populations d’utilisateurs, par exemple en fonction du sexe ou de l’origine ethnique ;
- La robustesse : mettre en place des mécanismes garantissant le fonctionnement fiable d’un système d’IA ;
- L’explicabilité : instaurer des mécanismes permettant de comprendre et d’évaluer les résultats d’un système d’IA ;
- La transparence : communiquer des informations sur un système d’IA afin que les parties prenantes puissent faire des choix éclairés quant à leur utilisation du système ;
- La gouvernance : déployer un processus pour définir, mettre en œuvre et appliquer au sein d’une organisation des pratiques responsables en matière d’IA.
AWS a poursuivi avec une présentation des 4 types de risques pouvant affecter le caractère “responsable” d’une IA Gen :
- Risque de non-véracité (ou hallucination) : pour illustrer ses propos, AWS a demandé à un système d’IA Gen de terminer la phrase « Walid Benabderrahmane habite … » et a affiché toute une série de réponses reçues …. toutes plus fausses les unes que les autres !
- Risques de toxicité et de manque de sureté : la production par un modèle de résultats nuisibles (haineux, menaçant, insultants ou dégradants) pour une personne ou groupe de personnes ou une utilisation abusive.
- Risque de non-respect de la propriété intellectuelle : l’absence de mécanismes au sein du modèle permettant d’identifier les œuvres protégées pour la propriété intellectuelle et/ou de limiter les usages contraires aux règles applicables dans ce domaine.
- Risque de perte de confidentialité des données : l’absence de mécanismes de protection des données et modèles contre le vol et la divulgation.
Pour limiter la matérialisation de ces risques, AWS propose une démarche de déploiement d’une IA responsable structurée autour de trois piliers. Cette démarche a été construite en s’appuyant sur un retour d’expérience de ces propres projets et pratiques internes :
- Pilier 1 – Mettre en place une responsabilité partagée entre les fournisseurs de services d’IA et les utilisateurs du modèle.
D’un côté, il convient de s’assurer que les fournisseurs mettent à disposition des services qui intègrent par défaut des mécanismes de protection visant à favoriser le développement d’une IA responsable. Par exemple, pour limiter les risques de toxicité et augmenter la sûreté du modèle, s’assurer que le fournisseur a implémenté des mesures de protection dans les modèles de base proposés (ex. : protection pour ne pas permettre au modèle de répondre à des questions sur des sujets illégaux), a changé les données utilisées pour entraîner le modèle et a ajouté des filigranes pour les données générées.
Côté utilisateurs, il est nécessaire de mettre en place à la fois des mesures fonctionnelles et techniques. D’un point de vue fonctionnel, on peut commencer par la mise en place d’une démarche d’analyse des risques spécifiques aux cas d’usage déployés (ex. : les impacts et mesures de protection ne sont pas les mêmes pour une IA qui génère de la musique et celle qui fournit des diagnostics médicaux) et aux modèles d’IA utilisés. Pour cela, il est possible de se référencer aux normes de référence dans le domaine, comme l’ISO 42001.2
- Pour limiter les risques d’hallucinations : faire du prompt engineering (développement et optimisation des prompts pour utiliser de façon plus efficace les LLM), définir des paramètres d’inférence (utilisation d’un modèle déjà entraîné pour effectuer des prédictions sur de nouvelles données, après la 1ère phase d’apprentissage), utiliser le RAG (Retrieval Augmented Generation – pour élargir la surface des données d’entraînement des modèles à des sources externes et donc potentiellement non encore explorées) et plus généralement faire du fine tuning en réentraînant le modèle sur des nouvelles données avec lesquelles il n’a pas été initialement exposé.
- Pour limiter les risques de toxicité et augmenter la sûreté du modèle : mettre en place des mesures de protection des services techniques utilisés, tester les biais et le contenu toxique et atténuer les biais détectés, suivre les politiques d’IA responsable.
- Pilier 2 – Intégrer les principes d’IA responsable dans tout le cycle de vie d’un modèle, c’est-à-dire lors …
De l’acquisition de données d’entraînement,du développement des modèles de base (FM),du pré-traitement des prompts utilisateurs,de l’évaluation des résultats
- Pilier 3 – Mettre en place une approche tournée vers les individus, pour engager toutes les parties prenantes dans le déploiement d’une IA Gen responsable : il s’agit de s’appuyer sur les personnes, les processus et la culture d’entreprise pour bâtir la confiance via :
- Des actions de sensibilisation et formation,la constitution d’équipes projet diversifiées (représentants IT, Métier, juridique, RH, …) et, au-delà, la mise en place d’une collaboration avec des organisations multipartites impliquées dans le développement d’IA responsables,
- De l’évaluation des impacts de l’IA en aval (dans le cadre d’un processus d’amélioration continue).
- De l’évaluation des impacts de l’IA en aval (dans le cadre d’un processus d’amélioration continue).
- L’adoption d’une approche holistique.
AWS a terminé sa conférence en rappelant les 4 facteurs clés de succès qui doivent accompagner tout programme de déploiement d’IA responsable :
- Poursuivre les actions d’exploration, car l’IA Gen responsable est un sujet encore nouveau et à défricher,
- Prioriser la formation et la diversité au sein des collaborateurs,
- Adopter des méthodes de gestion des risques et frameworks d’IA responsable,
- Tester, tester, tester (!)
Conclusion des conclusions
OUI, il est possible dès à présent de construire des applications d’IA sécurisées. Pour cela, il convient notamment :
- De s’appuyer sur un dispositif préalablement défini de gouvernance de ses données ;
- D’appliquer le principe du « shift left » et d’identifier dès la phase de conception les menaces spécifiques qui peuvent rendre les systèmes d’IA non sécurisés et/ou non-responsables.
Pour cela, il convient de définir en amont une méthodologie d’analyse de risque structurée, standardisée, et alimentée par des référentiels externes reconnus, idéalement adaptée aux enjeux propres à l’IA (cas d’usage et modèles).
J’espère que ce tour d’horizon des préconisations de sécurité des systèmes d’IA vous aura été utile. Si vous voulez en savoir plus, je vous propose de poursuivre par la lecture d’un article en 4 épisodes que j’ai rédigé récemment pour explorer de façon un peu plus complète le monde de l’IA sous l’angle cyber (historique de l’IA, inventaires des menaces et risques, état des lieux des lois et normes de références, propositions de mesures de sécurité et projections sur l’impact de l’IA sur l’amélioration de la boîte à outils du RSSI) ! Je vous souhaite une bonne poursuite de vos lectures, et surtout un beau voyage dans le monde de la sécurité de l’IA !
- Large Language Models : “modèles de langage possédant un grand nombre de paramètres, généralement de l’ordre du milliard de poids ou plus. Ce sont des réseaux de neurones profonds entraînés sur de grandes quantités de texte non étiqueté utilisant l’apprentissage auto-supervisé ou l’apprentissage semi-supervisé. Les LLM sont apparus vers 2018 et ont été utilisés pour la mise en œuvre d’agents conversationnels.”, Wikipedia ↩︎
- Norme qui spécifie les « exigences relatives à l’établissement, à la mise en œuvre, à la maintenance et à l’amélioration continue d’un système de gestion de l’IA (AIMS), qui permet de gérer les risques et les opportunités liés à l’IA. » (https://www.mirabilis.ai/) ↩︎


