Je vous entends déjà : “Encoooore un article sur l’IA !? On en voit déjà passer 15 par jour depuis que ChatGPT a fait sa première sortie publique en novembre 2022”. En effet… C’est ce que je me disais moi-même ! Jusqu’à constater que les informations que je lisais étaient très incomplètes et dispersées, et que je n’arrivais pas à trouver un contenu proposant une vue d’ensemble de l’état des risques spécifiques à l’IA, des réglementations et standards en cours de développement et des mesures de gouvernance et de protection qui pourraient être mises en œuvre dès maintenant. J’ai peut-être mal cherché, me direz-vous.
Tout à fait d’accord… Et en même temps, je vous répondrais qu’on n’est jamais mieux servi que par soi-même et que pour comprendre et apprendre un sujet, rien de mieux que de s’y immerger. Alors suivez-moi pour une exploration du monde de l’IA sous l’angle de la cyber ! Cet article s’adresse à un large public, du Chief Data Officier, DSI et responsable de la transformation numérique ou des services à la clientèle qui cherchent à déployer des systèmes d’IA efficients dans leur organisation au RSSI qui n’a rien contre l’idée… mais aimerait bien que cela se fasse sans pour autant mettre en péril la tranquillité de son sommeil ! Voire utiliser l’IA à l’avantage de la fonction sécurité, pour améliorer la posture cyber de son organisation !
Dans la 1ère partie de cet article, je commencerai par poser le décor : rappel de quelques définitions clés, résumé du développement des systèmes d’IA depuis les années 50 et aperçu de la croissance du secteur… et des avis des représentants du monde de l’IT et de la gestion des risques sur le niveau de préparation et de protection des organisations face à ces “nouvelles” technologies (vous pouvez d’ores et déjà sortir les mouchoirs, les antidépresseurs ou le whisky…).
Dans une deuxième partie, je présenterai un résumé des risques et attaques clés spécifiques au monde de l‘lA (top 10 de l’OWASP, norme ISO, travaux du NIST, de NUMEUM en France, etc.) ainsi qu’un état des lieux des lois, réglementations, normes et standards, au niveau des instances internationales mais aussi dans différentes régions et pays du monde (et c’est là que nous verrons que si l’Europe prépare l’IA Act, les États-Unis ne sont pas non plus en retard dans la promulgation de bills et autres textes encadrant la pratique de l’IA).
Je proposerai dans les deux dernières parties des suggestions pour préparer votre organisation à l’arrivée des technologies d’IA et mettre à jour les pratiques d’analyse de risques en conséquence, une checklist de mesure de protection et réaction, ainsi qu’un aperçu du futur de l’IA pour la fonction SSI (oui amis RSSI, l’IA pourrait devenir votre meilleure alliée… en complément de la caféine 😊).
On pose le décor
Une (très) courte histoire de l’IA
Il semble faire consensus que bébé IA soit né à l’été 1956, au cours de la conférence de Dartmouth (Dartmouth Summer Research Project on Artificial Intelligence). A l’époque, et pour les années qui ont suivi, l’objectif était principalement d’utiliser l’IA pour démontrer des théorèmes mathématiques (à titre d’exemple, le programme Logic Theorist présenté lors de la conférence de Dartmouth) ou résoudre des problèmes. John Mc Carthy, présenté depuis comme le père fondateur du terme “Intelligence artificielle”, présenta à Darmouth un algorithme d’évaluation utilisé par la suite pour programmer la plupart des programmes de jeux d’échecs.
L’IA a ensuite investi le domaine de la traduction automatisée, puis a été utilisée pour améliorer les dispositifs de robotique (au point qu’en juin 2023, les chercheurs de Google DeepMind ont présenté RoboCat, 1er robot capable de s’améliorer tout seul). Mais dans les années 80, le monde de l’IA a connu un premier coup d’arrêt : les sommes investies dans le sujet étaient jugés trop importantes au regard des retours sur investissements à court et moyen termes qu’on pouvait espérer.
Puis la machine a été relancée au courant des années 90, avec le déploiement massif de l’informatique dans les entreprises, les tous débuts de la digitalisation et la prise de conscience en corolaire de la plus-value possible de l’IA dans le monde des “systèmes experts” (outil de résolution de problème basé sur des règles prédéfinies et une base de connaissance préconstituée, dont les premières versions remontent à 1965).
L’IA a continué à se développer et s’améliorer au rythme de l’évolution de l’informatique (notamment l’augmentation de la puissance de calcul et des capacités de stockage en parallèle d’une baisse des coûts associés, merci le cloud !) et de la révolution de la data (plus de données disponibles en ligne, amélioration des outils d’extraction et de traitement, cas d’usage business croissants). Ainsi, si les technologies plus anciennes et le Machine learning ont été intégrés dans les SI depuis un long moment, l’IA a franchi un nouveau cap en cela qu’elle n’est plus là uniquement pour accélérer ou automatiser des traitements humains mais aussi apprendre, créer du contenu et finalement faire évoluer le monde qui nous entoure. Cela correspond à la vague des solutions d’IA génératives et de LLMs (Large Language Models), avec comme “acte fondateur » (pour le grand public) la sortie de ChatGPT.
Quelques définitions
L’Intelligence Artificielle : selon Malik Ghallab, Directeur de recherche emeritus au CNRS, l’IA repose sur quatre fonctions, qui s’appuie sur des données de différents types (“données, connaissances et modèles génériques, préférences, règles de conduite, etc.”). Ces 4 fonctions sont :
- Percevoir (“Interpréter des signaux transmis par des capteurs (caméras, microphones, etc.) se rapportant à des objets, des personnes, des sons”) ;
- Raisonner (“Démontrer diagnostiquer, prédire, proposer, expliquer, décider planifier”) ;
- Agir et interagir (“Agir sur l’environnement, se mouvoir, déplacer des objets, communiquer et interagir avec d’autres agents “) ;
- Apprendre (“Acquérir et améliorer des facultés et des connaissances, apprendre à reconnaître des objets, des situations”).
Méthodes d’apprentissage “classiques”: on peut relever 3 principales méthodes d’apprentissage dites “classiques” :
- L’apprentissage supervisé : tâche d’apprentissage automatique “consistant à apprendre une fonction de prédiction à partir d’exemples annotés”
- L’apprentissage non-supervisé : tâche d’apprentissage automatique “où les données ne sont pas étiquetées (par exemple étiquetées comme « balle » ou « poisson »). Il s’agit donc de découvrir les structures sous-jacentes à ces données non étiquetées. Puisque les données ne sont pas étiquetées, il est impossible à l’algorithme de calculer de façon certaine un score de réussite. Ainsi, les méthodes non supervisées présentent une auto-organisation qui capture les modèles comme des densités de probabilité ou, dans le cas des réseaux de neurones, comme combinaison de préférences de caractéristiques neuronales encodées dans les poids et les activations de la machine.
- “Apprentissage par renforcement” : tâche d’apprentissage automatique qui “consiste, pour un agent autonome à apprendre les actions à prendre, à partir d’expériences” et reçoit en retour de son environnement « une récompense, positive ou négative. L’agent cherche alors, “au travers d’expériences itérées, un comportement décisionnel optimal, en ce sens qu’il maximise la somme des récompenses au cours du temps”.
Il est à noter qu’il existe un 4e type d’apprentissage, à mi-chemin de l’apprentissage supervisé et non-supervisé, à savoir l’apprentissage semi-supervisé : tâche d’apprentissage automatique qui “utilise un ensemble de données étiquetées et non étiquetées” en vue “d’améliorer significativement la qualité de l’apprentissage”.
L’apprentissage “Deep learning”: le deep learning qualifie les tâches d’apprentissage où une machine apprend à effectuer une tâche sans qu’aucun être humain ne lui indique au préalable la méthode à utiliser. La machine va s’appuyer pour cela sur un réseau de neurones artificiels et apprendre de son environnement et de ses erreurs. Le machine learning lui nécessite l’intervention de l’être humain dans le processus d’apprentissage (voir les définitions d’apprentissages “classiques” ci-dessus). L’avantage du ML est qu’il peut se mettre en œuvre avec un jeu relativement restreint de données d’entrainement, alors que le DL nécessite d’importants volumes de données pour affiner son apprentissage.
L’IA générative : il s’agit d’un “type de système d’IA capable de générer du texte, des images ou d’autres médias en réponse à des invites (prompts). Elle est dite multimodale quand elle est construite à partir de plusieurs modèles génératifs, ou d’un modèle entraîné sur plusieurs types de données et qu’elle peut produire plusieurs types de données. Par exemple, la version GPT-4 d’OpenAI accepte les entrées sous forme de texte et/ou d’image”.
Les LLMs(Large Language Models) : il s’agit de “modèles de langage possédant un grand nombre de paramètres (généralement de l’ordre du milliard de poids ou plus). Ce sont des réseaux de neurones profonds entraînés sur de grandes quantités de texte non étiqueté utilisant l’apprentissage auto-supervisé ou l’apprentissage semi-supervisé. Les LLM sont apparus vers 2018 et ont été utilisés pour la mise en œuvre d’agents conversationnels.”
Les usages en quelques chiffres
Selon une étude publiée en février 2024 par le cabinet Strand Partners pour AWS, “2023 aurait été une année charnière pour l’adoption de l’IA dans l’Hexagone, qui fait figure de bon élève au niveau européen” (ça nous change des classements Pisa…). » La France a ainsi “connu une hausse de 35% du nombre d’entreprises ayant adopté l’IA par rapport à 2022. (…) Précisément, c’est l’adoption des grands modèles de langage (LLMs) et plus généralement l’IA générative qui a contribué à hauteur de 68% à cette adoption massive de la technologie”.
Début 2024, Techopedia a publié toute une série de statistiques sur l’IA en 2024. On y apprend notamment que selon Grand View Research, le marché de l’IA représente déjà 136,55 milliards de dollars et il prévoit un taux de croissance annuel composé de 37,3 % entre 2023 et 2030. Selon l’enquête annuelle de 2022 de NewVantage Partners, 91 % des grandes organisations investissent dans des activités d’IA, et environ le même nombre déclare que leur investissement dans les données et les activités d’IA augmente d’année en année. 92 % des entreprises obtiennent déjà des retours sur ces investissements. De fait, l’étude mondiale sur l’intelligence artificielle de PwC prévoit que la technologie de l’IA pourrait apporter 15,7 billions de dollars supplémentaires à l’économie mondiale d’ici 2030. Cela équivaut à une augmentation du PIB de 26 % en Chine et de 14,5 % en Amérique du Nord. Ces deux régions représentent ensemble près de 70 % du total des gains attendus au niveau mondial.
Ces informations peuvent être mises en regard de celles contenues dans un article publié sur le site de Supelec et qui présente quelques macros-cas d’usages de l’IA, par secteur d’activités :
- Industrie : l’IA est utilisée dans l’industrie pour automatiser les processus de production, optimiser les chaînes d’approvisionnement et améliorer l’efficacité énergétique. Elle est également utilisée pour effectuer des analyses prédictives de la qualité et de la performance des produits, ainsi que pour détecter et diagnostiquer les problèmes de maintenance.
- Santé : l’Intelligence artificielle est utilisée dans le secteur de la santé pour aider les médecins à diagnostiquer et traiter les maladies, pour optimiser les protocoles de traitement et pour élaborer des plans de traitement personnalisés. Elle est également utilisée pour analyser les données médicales et pour effectuer des recherches sur les nouvelles thérapies et traitements.
- Secteur public : elle peut être utilisée dans le domaine public pour améliorer l’efficacité et la qualité des services rendus aux citoyens. Elle peut être utilisée pour automatiser certaines tâches administratives, pour optimiser les processus de prise de décision et pour analyser les données afin de mieux comprendre les besoins des citoyens et de mettre en place des politiques publiques efficaces.
- Sécurité : dans le secteur de la sécurité, on s’en sert pour détecter et prévenir les activités criminelles, pour analyser les données de surveillance et pour aider à la prise de décision en cas de crise. Elle est également utilisée pour protéger les réseaux informatiques contre les cyber-attaques et pour détecter les comportements suspects” (nous y reviendrons d’ailleurs dans la dernière partie de cet article).
Des cas d’usage à foison et une volonté d’investissements massifs partout dans le monde, une vraie manne pour tous les fournisseurs du monde de l’IT, de Nvidia qui explose tous les records de bénéfices (en tant que fournisseur majeur des puces électroniques qui équipent les systèmes d’IA) aux principaux fournisseurs cloud qui étoffent jour après jour leur catalogue de services d’IA et ML. A titre d’exemple, on peut citer AI Studio d’Azure (en mode public preview), ainsi que sa suite d’outils AKA cognitive Services, l’offre Vertex AI de GCP, enrichie de capacités d’IA générative et le duo de service d’AWS Bedrock & SageMaker, lui aussi nourri à l’IA. A ce titre, et selon une étude de Wiz menée sur 150 000 comptes de cloud publics, 70% des environnements cloud utilisent désormais une de ces 3 familles services d’IA.
Alors, tout va pour le mieux dans le meilleur des mondes ? Mhummmm, modulo que toute technologie apporte son lot de nouvelles menaces et risques, ou du moins une actualisation des vecteurs d’attaques et/ou une amplification de la fréquence ou des impacts…
Selon une enquête de PWC publiée en janvier 2024 et réalisée auprès de plus de 4 7000 CEO, pour 64% d’entre eux l’IA générative est susceptible d’accroître le risque de cybersécurité pour leur entreprise au cours des 12 prochains mois. De son côté le Gartner estime, dans une étude publiée en décembre 2023, que l’adoption de l’IA générative sera la question la plus importante pour les responsables juridiques, conformité et DPO au cours des deux prochaines années. La firme de recherche Ponemon Institute complète cette prévision, à la suite d’une enquête menée auprès de 1 917 professionnels de la sécurité IT aux EU, UK, France, Allemagne et Australie : “La moitié des répondants croient que les technologies avancées comme la GenAI réduisent considérable le temps pour mener une attaque et disent que la technologie peut énormément augmenter le nombre d’attaques lancées sur une seule journée. De plus, seulement 39% des répondants croient que leur infrastructure de sécurité est adéquatement adaptée pour offrir une protection contre les attaques automatisées alimentées à la GenAI.”
Voilà où le bât blesse. Non seulement ça risque de faire très vite très mal… mais, guess what ? la boîte à outils pour se protéger ou, a minima, réagir au plus vite n’est pas prête ! Et Riskonnect en rajoute une couche ! Après avoir mené un sondage auprès de 300 professionnels du risque et de la conformité, l’entreprise affirme que 93% des entreprises anticipent des menaces significatives associées à l’IA mais que seulement 17% ont formé ou briefé l’ensemble de leurs collaborateurs sur les risques associés à son usage, et seulement 9% disent qu’ils sont préparés à les gérer.
Voilà, voilà….
Au niveau de la France, est-on mieux loti ? Selon le baromètre 2024 de la cybersécurité, produit par Opinionway pour le compte du CESIN, “L’IA est désormais utilisée dans la moitié des SI” des répondants mais pour la grande majorité aucune stratégie de sécurité n’a encore été définie permettant sa bonne prise en compte sécurité (30% des 46%). Il est à noter que selon ce baromètre pour 43% des répondants l’IA n’est pas officiellement utilisée en interne et son intégration s’apparente pour le moment à du Shadow IT…
Voilà, voilà, voilà….
- En 2023, des employés de la firme sud-coréenne Samsung ont alimenté à trois reprises ChatGPT avec des données internes (code source d’un programme de téléchargement d’une base de données pour identifier un bug d’exécution, code source d’une application en vue d’en demander l’optimisation, chargement de l’enregistrement d’une réunion pour en obtenir un support de présentation) …. Oupsy….
- A l’automne 2023, l’équipe de recherche en IA de Microsoft a intentionnellement publié en libre accès sur GitHub un ensemble de données de formation, mais a accidentellement exposé en cadeau bonus 38 téraoctets de données internes, dont une sauvegarde du disque dur des postes de travail de deux employés, contenant des secrets, clés privées, mots de passe et plus de 30 000 messages internes de Microsoft Teams… Re-Oupsy….
Est-ce que cela a influencé Google. En tout cas, la firme américaine a récemment créé une « AI Red Team » et a annoncé le 26 octobre 2023 étendre son programme de bug bounty (le Vulnerability Reward Program) aux scénarios d’attaques spécifiquement liées à l’IA générative. A la même période, OpenAI a créé sa propre équipe dédiée à la préparation des « risques catastrophiques » (sic) et à la sécurité des systèmes d’IA hautement performants.
Conclusion
En synthèse, de l’IA, tous les secteurs d’activités en font et vont continuer à en faire de plus en plus. ET le monde de la cyber n’est pas encore complètement, complètement prêt à cette déferlante… Alors, soit on regarde ailleurs pendant que le château brûle (en priant pour que ça soit surtout celui du concurrent) soit on se retrousser les manches et on s’approprie le terrain de l’IA ! On se retrouve dans la deuxième partie de cet article pour faire un focus sur les risques et attaques précises contre lesquelles se protéger et les réglementations, normes et référentiels qui nous fournissent les premières armes pour y répondre.
Deuxième partie
Dans la première partie de cet article sur l’IA & et la cyber, nous avons commencé par poser le décor (définitions clés, historique du développement de l’IA depuis les années 50 et bilan de l’état en cours du déploiement et du niveau de préparation des équipes cyber, conformité, risques et juridiques).
Dans cette deuxième partie, nous allons passer en revue un résumé des risques et attaques clés spécifiques au monde de l‘lA ainsi qu’un aperçu des principaux travaux en court en termes de lois, réglementations, normes et standards internationales, régions et nationales.
Je vous proposerai dans les deux dernières parties des suggestions pour préparer votre organisation à l’arrivée des technologies d’IA et mettre à jour les pratiques d’analyse de risques en conséquence, une check-list de mesure de protection et réaction et un aperçu du futur de l’IA pour la fonction SSI.
On est parti !
Petit aperçu des attaques et des risques liés à l’usage l’IA
Les attaques liées à l’IA peuvent être classées grosso modo en deux catégories.
Première catégorie, celles qui utilisent l’IA pour améliorer de techniques d’attaques existantes ou leur volume / fréquence : dans cette catégorie on retrouve par exemple les malwares adaptatifs, polymorphiques et ceux à propagation autonome. Autre terrain propice : le phishing, via l’aide précieuse des IA pour forger des emails et sites web parfaites copies des sites légitimes de référence. A titre d’exemple, un rapport publié par SlashNext souligne une augmentation de 1 265% des emails malicieux de phishing entre fin 2022 et le troisième trimestre 2023 grâce à l’usage des techniques d’IA.
Mais ce n’est pas cette catégorie d’attaques “boostées à l’IA” sur laquelle je vais me concentrer ans cet article. Je vais porter mon attention uniquement sur les attaques qui visent les systèmes d’IA eux-mêmes. Pour cela, je vous propose d’utiliser comme support le tableau ci-dessous de taxonomie des attaques d’un système ci-dessous produit par le Laboratoire d’Innovation Numérique de la CNIL (LINC) dans son dossier “Sécurité des systèmes d’IA” d’avril 2022.
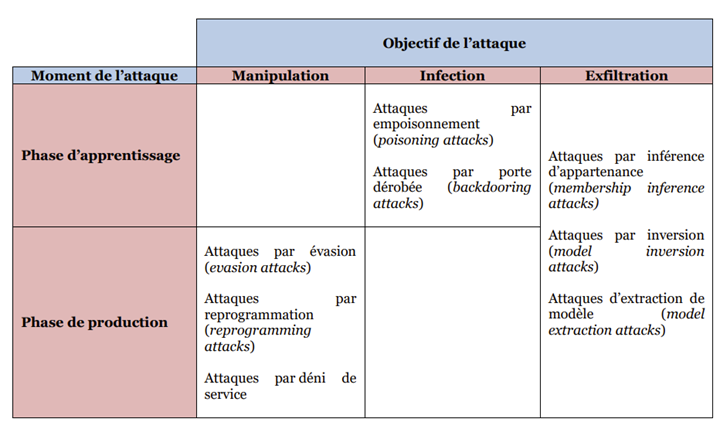
Pour illustrer cette taxonomie, le LINC présente des schémas et exemples concrets d’attaque, que je résume ci-dessous. Pour plus d’informations, je vous encourage vivement à lire le dossier complet du LINC :
- Les attaques par manipulation : visent à contourner le comportement attendu des IA voire à leur faire réaliser des tâches non inattendues :
- Manipulation par évasion (evasion attacks) : ces attaques se produisent après le déploiement d’un système d’IA et visent à détourner le fonctionnement de l’IA en lui fournissant des données contradictoires (adversarial example) afin de lui faire produire à termes des prédictions erronées. Il s’agit par exemple de lui fournir deux images sensées présentées le même objet mais dont l’une contient un “bruit”, une ”illusion optique”. Ou deux groupes de caractères censés être similaires mais avec un léger inversement de caractères dans un des deux cas. Ces attaques représentent la très vaste majorité des attaques des systèmes d’IA.
Ex. : changer quelques pixels dans une image avant de la fournir au système d’IA, pour induire une erreur dans le travail de classification du système de reconnaissance.
- Manipulation par reprogrammation (reprogramming attack) : ces attaques visent à faire réaliser une action par l’IA en reprogrammant à distance l’algorithme utilisé pour une tâche.
Ex. : ces attaques peuvent amenées à des actions malicieuses très variées, comme le vol de données, ou le détournement des systèmes d’IA pour leur faire réaliser des actions contraires aux principes éthiques initiaux voir même des activités d’espionnage.
- Manipulation par déni de service : ces attaques visent par exemple à surcharger les systèmes jusqu’à impacter leur disponibilité de façon significative en lui soumettant un nombre important de requêtes très consommatrices.
- Les attaques par infection : visent à prendre le contrôle du fonctionnement d’un système d’IA de façon dissimulée
- Infection par empoisonnement (poisoning attack) : se produisent pendant la phase d’apprentissage par l’introduction de données corrompues afin de diminuer la qualité des décisions de l’IA. Les attaques par empoisonnement diffèrent des attaques par évasion du fait des restrictions éventuelles / conditions de réalisation de l’attaque : capacité des attaques à viser une cible pré-identifiée ou pas, possibilité d’injecter tout type de données ou uniquement certaines catégories, possibilité d’injecter et d’étiqueter des données ou seulement un des deux ? Les modifications peuvent en effet porter sur les étiquettes des ensembles de données (label modification), l’envoi de nouvelles données d’entraînement (data injection), la modification des données d’entraînement lorsque l’attaquant peut accéder aux ensembles réellement utilisés (data modification) et la modification de l’algorithme d’apprentissage lui-même (logic corruption).
Ex. : ce type d’attaque, parmi les plus fréquentes, est utilisée par exemple pour tromper les classifieurs de spams.
- Infection par abus (non citée dans le tableau du LINC) : impliquent l’insertion d’informations incorrectes dans une source que l’IA absorbe ensuite. A la différence des attaques par empoisonnement, il s’agit de fournir une information erronée provenant d’une source légitime mais compromise
- Infection par Backdooring(backdooring attack – à noter que cette sous-catégorie inclut notamment les attaques dites Backdoor Trojan, qui ciblent les réseaux neuronaux profonds des modèles de Deep Learning) : dans ce cas, l’attaquant parvient à empoisonner l’IA en ayant accès à son modèle et ses paramètres en vue de réentraîner ce modèle. Le modèle, une fois infecté, sera utilisé par des utilisateurs légitimes.
Ex. : la plupart du temps les entreprises qui utilisent des systèmes d’IA ne créent pas leur modèle ex nihilo mais réutilisent des modèles de reconnaissance existants et les réentraînent avec de nouveaux ensembles de données. Ces modèles peuvent être téléchargés sur internet, et avoir été modifiés au préalable par des pirates qui les auraient remplacés par une version malicieuse.
- Les attaques par exfiltration : visent à voler des données utilisées par un système d’IA (données d’entraînement, modèle, données liées aux algorithmes, …)
- Exfiltration par inférence d’appartenance (membership inference attack) : l’objectif est d’identifier si un point spécifique de données a été utilisé pour l’apprentissage du modèle et de s’appuyer sur cette information pour inférer les attributs à la source de ces données, et donc découvrir des informations potentiellement sensibles sur cette source.
- Exfiltration par inversion de modèle – ou extraction de données (model inversion attack) : vise à reconstruire les données utilisées pour l’apprentissage de l’IA en soumettant un grand nombre de données au système et en observant les résultats en sortie. Il s’agit d’une attaque très difficile à mettre en œuvre, dans la mesure où elle nécessite une connaissance approfondie et un accès à haut privilège au système d’IA.
Ex. : les deux types d’attaque citées ci-dessus pourraient par exemple permettre à un attaquant de tester un système d’IA qui réalise des analyses médicales sur base d’informations personnelles. Si un pirate peut utiliser une attaque par inférence d’appartenance ou inversion de modèle pour déterminer si.quels antécédents médicaux d’une personne cible font partie des données d’entraînement, il pourrait utiliser cette information pour nuire à la personne cible ou la discriminer par des tiers.
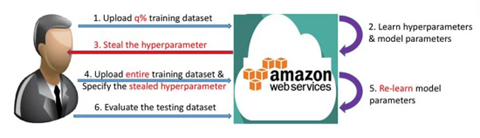
- Exfiltration par extraction de modèle (model extraction attack) : cette attaque vise à voler le modèle lui-même ou ses paramètres, sachant qu’il s’agit du cœur même du système, donc de sa composante ayant la plus grande valeur. Il s’agit d’un type d’attaque encore relativement peu commune.
Ex. : le schéma ci-dessous schématise une attaque théorique par extraction de modèle décrite dans une étude publiée en 2013 “Hacking smart machines with smarter ones: how to extract meaningful data from machine learning classifiers”
Si on se place sous un angle opérationnel, on peut se référer aux travaux de l’OWASP, qui a produit son top 10 des vulnérabilités liées à l’usage l’IA :
- LLM01 : Injection de prompt
- LLM02 : Traitement non sécurisé des sorties
- LLM03 : Empoisonnement des données d’apprentissage
- LLM04 : Déni de service du modèle (DoS)
- LLM05 : Chaîne d’approvisionnement
- LLM06 : Divulgation d’informations sensibles
- LLM07 : Conception de plug-ins non sécurisée
- LLM08 : Excès de pouvoir de décision
- LLM09 : Excès de confiance
- LLM10 : Vol de modèle
En complément, OWASP a formalisé une matrice de la sécurité des systèmes d’IA très bien structurée, classifiant les surfaces d’attaques, menaces, ressources cibles, catégorie et type d’impacts en fonction des états du système :
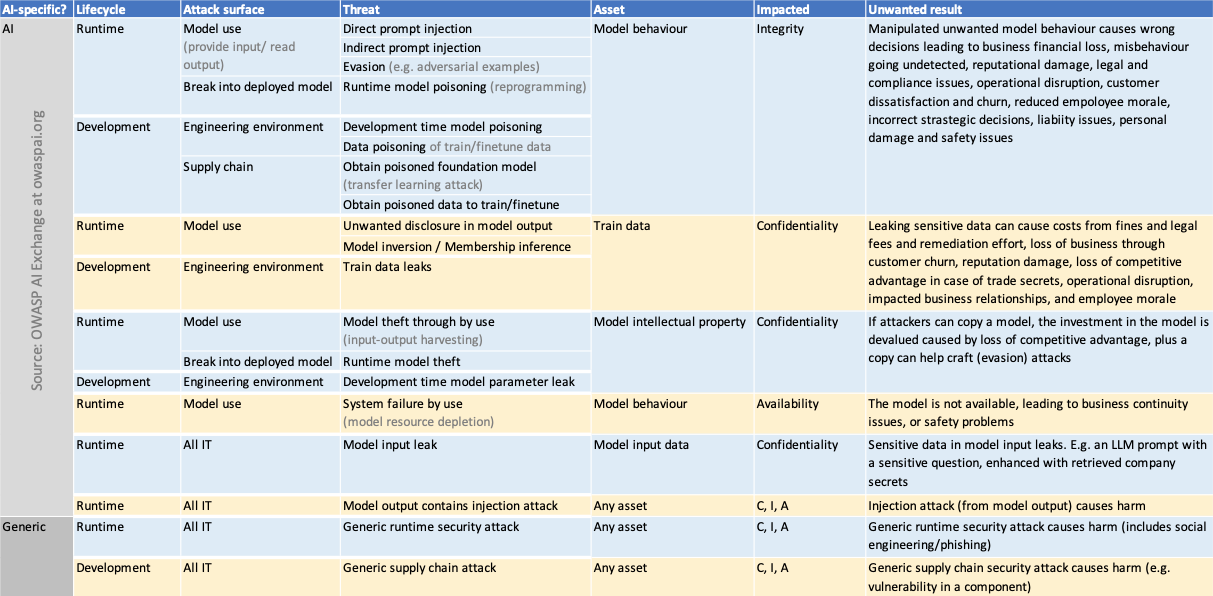
Ce tableau nous montre que les menaces et vulnérabilités entraînent des conséquences souvent relativement classiques mais applicables à des contextes nouveaux :
- Risque de perte d’intégrité, en raison de la manipulation / empoissonnement des données, injection d’éléments de biais, etc.
- Risque de fraude, par l’usage inapproprié ou détourné des systèmes d’IA. Ainsi le World Economic Forum a indiqué dans son Global Risks Report 2024 que le principal risque pour les deux années à venir était le risque de la désinformation ou mésinformation basée sur l’IA.
- Risque de vol et/ou pertes d’information, que ce soit lors des phases d’entraînement ou de mise à jour post mise en production.
- Risque d’indisponibilité des SI, notamment sur des SI qui n’ont pas été configurés pour gérer la limitation de ressources.
Sans oublier le risque de non-conformité aux lois et règlements nationaux, régionaux, internationaux et sectoriels. Certains secteurs comme ceux de la santé et de la finance sont encadrés par des règles d’usage des modèles d’AI très strictes.
Dans une étude menée en mai 2023 auprès de 249 RSSI à propos des 20 risques émergents, le Gartner souligne d’ailleurs que « L‘IA générative apparaît comme le deuxième risque le plus souvent cité dans notre enquête du deuxième trimestre, apparaissant dans le top 10 pour la première fois ».
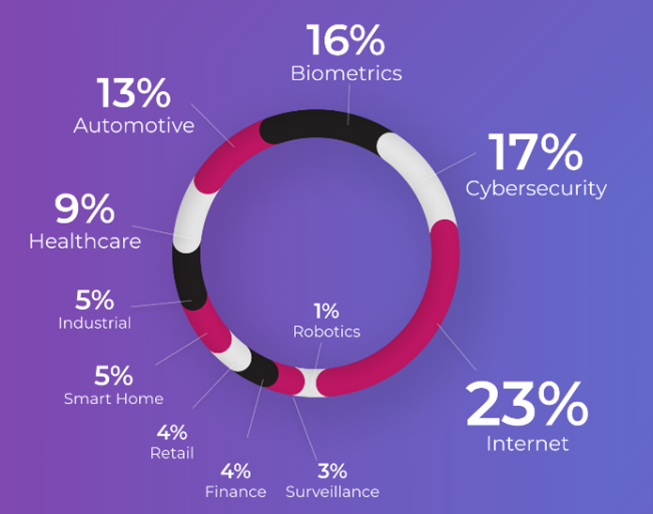
D’ailleurs, quelles sont les domaines d’activités et les applications d’IA les plus à risque d’être attaquées ? Dans un rapport d’avril 2021, la startup israélienne Adversa, spécialisée dans la sécurité des systèmes d’IA, a publié son top 10 des industries les plus ciblées et des applications d’AI les plus attaquées :
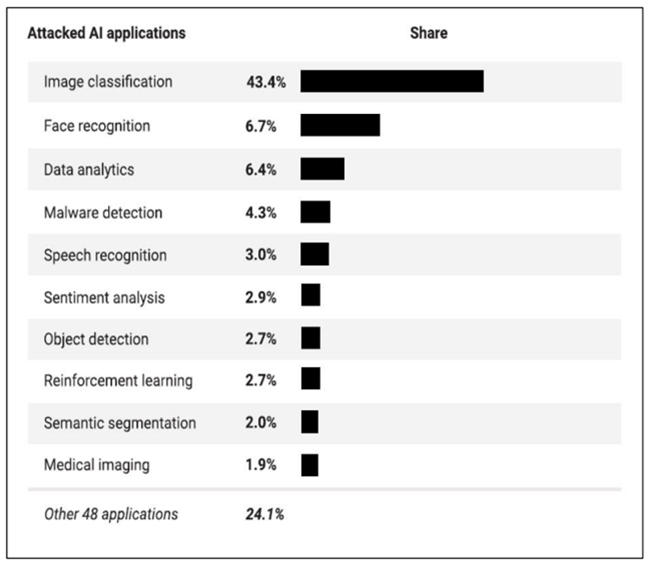
Référentiels, lois et normes
Et en parlant de lois et règlements, justement… Parfaite transition que je me sers sur un plateau !
Un des supports au déploiement massif mais sécurisé des services d’IA est, pour commencer, la définition de normes claires et de principes de gouvernance solides, servant de garde-fous à tous les acteurs du domaine.
Vous trouverez ci-dessous une liste (absolument non exhaustive) de lois, règlements, normes, standards, référentiels disponibles ou en cours de rédaction / mise en œuvre. J’ai cherché à travers cet inventaire (un peu à la Prévert) à fournir des références qui se complètent les uns les autres, et qui tendent à montrer également que des réflexions sont déjà en cours sur l’ensemble des sujets, et dans la plupart des pays principalement impliqués sur le sujet de l’IA.
Dans le monde
- L’ISO 42001 (parce qu’il y a toujours une norme ISO…) : cette norme internationale définit les exigences en vue d’établir, mettre en œuvre, tenir tenue à jour et assurer l’amélioration continue d’un système de management de l’intelligence artificielle (SMIA) au sein d’un organisme. SMIA, SMSI… cela vous rappelle-t-il quelque chose de familier amis de la SSI ? 😉 L’objectif de cette norme est de “permettre aux organismes qui proposent ou utilisent des produits ou services sollicitant une IA de veiller au développement et à l’utilisation de ces systèmes de manière responsable.”
- L’OWASP AI Exchange (et l’OWASP LLM Top 10 list) : il s’agit d’une initiative collaborative visant à produire un guide open-source de sécurisation des composants d’IA (menaces, vulnérabilités et contrôles). Il a aussi publié des « bills of material” (BOM) de l’AI et du ML (liste exhaustive des composants d’un produit) pour aider à limiter les risques liés à la supply chain. Il utilise pour cela le MITRE ATLAS’s ML Supply Chain Compromise (Adversarial Threat Lanscape for Artificial Intelligence Systems) : une base de connaissance des méthodes, techniques et études de cas d’attaques menées contre des systèmes d’apprentissage automatique.
- De leur côté, les Nations Unis ont décidé de mettre en place au sein de l’Unesco l’Inter-Agency Working Group on AI ainsi qu’un organe consultatif de haut niveau placé sous l’autorité du secrétaire général.
En Europe
- L’AI Act : l’AI Act n’est pas encore en vigueur mais 2024 a marqué une avancée significative avec l’adoption le 2 février 2024 par la Commission européenne du « Règlement établissant des règles concernant l’intelligence artificielle ». L’AI Act regroupe un ensemble de règles et d’usages, applicables en fonction du niveau de risque pré-identifié. Il existe 5 niveaux de risques :
- Inacceptable : qualifie tout ce qui va à l’encontre des valeurs et droits fondamentaux de l’UE, comme les usages qui pourraient manipuler des personnes sans qu’elles en aient conscience ou modifier le comportement de groupes vulnérables, comme les enfants, au point de leur causer des dommages physiques ou psychologiques
- Élevé : se rapporte principalement aux usages dans les secteurs de la santé, de l’éducation, du recrutement, de la gestion d’infrastructures critiques, du maintien de l’ordre ou de la justice
- IA générative à usage général : cette catégorie a été créée en 2023 à la suite de la montée en puissance des IAGen comme ChatGPT. Ces systèmes doivent “suivre un processus approfondi d’évaluation et rapporter tout incident grave à la Commission européenne »
- Limité : se rapporte notamment aux usages liés à la manipulation d’images, de son ou vidéos. Les obligations pour ces systèmes sont surtout des exigences de transparence vis à vis de leurs utilisateurs
- Minimal : se rapporte notamment aux IA utilisés pour les jeux vidéo ou les filtres anti-spam. Dans ce cas, aucune obligation pour leur fournisseur mais la recommandation de suivre un code de conduite
Parmi les règles à respecter, on retrouve des exigences en termes de transparence, de protection des données, de bonnes pratiques quant à l’usage des données d’entraînement des modèles, de cartographie et de qualité des données (origine, emplacement). L’IA Act impose aussi de savoir expliquer le fonctionnement du système (à noter que l’on retrouve ici un point commun avec le RGPD, qui impose lui aussi la capacité à expliquer les traitements réalisés sur les données personnelles). Cette traçabilité sera exigée lors des phases d’audit, qui font partie des mesures inscrites au règlement.
Il est à notre qu’en cas de non-respect, les pénalités pourraient être très lourdes, jusqu’à 7% du chiffre d’affaires, plafonnées à 35 millions d’euros.
- Mais l’Europe n’est pas que des lois ! Dès avril 2029 le GEHN IA (groupe d’experts de haut niveau sur l’IA) a publié un “Ethics guidelines for trustworthy AI” puis en juillet 2020 il a mis à disposition l’outil ALTAI (Assessment List on Trustworthy Artificial Intelligence). Il s’agit d’une liste, créée grâce aux contributions de plus de 350 intervenants, qui vise à aider les développeurs et personnes en charge du déploiement d’IA à créer une IA digne de confiance.
En France
- L’ANSSI a publié fin avril ses « Recommandations de sécurité pour un système d’IA générative » : ce guide contient une présentation des architectures IA types et menaces associées, des principes d’une analyse de risques dédiée aux systèmes d’IA puis une série de recommandations techniques et fonctionnelles d’ordre général, mais aussi spécifiques aux phases d’entraînement, de déploiement, de production, à la génération de code source assistée par l’IA, aux services d’IA grand public exposés sur Internet et à l’utilisation de solutions d’IA générative tierces.
- Il existe aussi plusieurs autres référentiels facilitant l’évaluation des systèmes d’IA, comme par exemples le guide d’auto-évaluation de son système d’IA publié par la CNIL, le référentiel d’évaluation data science responsable et de confiance de l’association Labelia ainsi que le guide pratique pour des IA éthiques du syndicat professionnel NUMEUM.
- Je citerais aussi le dossier “Sécurité des systèmes d’IA” produit par le Laboratoire d’Innovation Numérique de la CNIL (LINC) en avril 2022, très étoffé, et qui présente une taxonomie détaillée et accessible des attaques des systèmes d’IA, complétée d’une méthodologie adapte d’analyse de risque et de propositions de mesures de protection à la fois des ressources utilisées et des processus d’apprentissage
- Il est à noter que le laboratoire national de métrologie et d’essai fournit quant à lui une certification de processus pour l’IA.
Aux États-Unis
- En octobre 2023, l’administration Biden a publié un “Executive Order” pour un développement et un usage sûr des systèmes d’IA. L’objectif est de fournir des orientations et critères de référence pour l’évaluation des capacités des systèmes d’IA, incluant un focus sur les fonctionnalités pouvant causer des dommages. “Rien qu’en 2023, 190 projets de loi ont été déposés au niveau des États pour réglementer l’IA, et 14 sont devenus des lois » soulignent Michele Goetz, analyste principale, et Alla Valente, analyste principale chez Forrester dans un billet de blog.
- De même, les membres de la Chambre des représentants des États-Unis ont formé un groupe de travail bipartisan qui « s’efforcera de produire un rapport complet comprenant des principes directeurs, des recommandations tournées vers l’avenir et des propositions politiques bipartisanes élaborées en consultation avec les comités compétents », indique le communiqué de presse annonçant le groupe de travail.
- De son côté, l’agence CISA (Cybersecurity and Infrastructure Security Agency) a publié une série d’orientations non contraignantes”, en collaboration avec les régulateurs britanniques. Il a aussi créé une feuille de route IA qui positionne des actions clés à mener par le CISA (en lien avec l’EO IA), complétées d’actions définies en propre ; l’objectif étant de fournir une aide aux propriétaires et opérateurs d’infrastructures critiques dans l’adoption de l’IA
- Plusieurs agences gouvernementales ont également nommé des Chief AI Officers en charge de coordonner l’usage de l’AI par leur agence et de promouvoir les innovations liées à l’AI tout en gérant les risques associés.
- Enfin le NIST a publié sa 1ère itération de son risk management framework specially for AI. A la base il s’agissait d’un guide basé sur le volontariat et non obligatoire mais un projet de loi déposé au Sénat en novembre 2023 et à la Chambre des représentants début 2024 tend à le rendre obligatoire pour les agences fédérales et les fournisseurs de solutions. La mise en oeuvre de ce framework est détaillée dans le Adversarial machine learning: a taxonomy and terminology of attacks and litigations (NIST. AI. 100-2). Sous l’impulsion du gouvernement américain, le NIST est également en train de créer l’AISI (Artificial Intelligence Safety Institute), un institut visant à exploiter le potentiel de l’IA tout en atténuant ses risques et réunissant notamment OpenAI, Meta, Microsoft, Amazon, Intel, Nvidia et Google.
- Du côté des fournisseurs IT, dans le cadre de son AI Cyber Defense Initiative, Google a publié en 2023 le référentiel « Secure AI Framework” (SAIF), qui vise à aider à mitiger les risques et menaces associés aux systèmes d’IA (vol de modèle et autres données confidentielles, attaques par injection dont par empoisonnement, attaque par injection malicieuse dans le prompt).
- Pour sa part AWS a notamment publié en octobre 2023 sa Generative AI security scoping matrix, pour aider à aborder les implications sécurité (gouvernance et conformité, législation et protection de la confidentialité, gestion des risques, contrôles et résilience) en fonction du type de workload d’IA générative déployés.
Ailleurs
Pour terminer ce tour d’horizon, quelques mots sur les actions menées par d’autres pays hors Europe et États-Unis :
- Le Royaume-Uni a publié en novembre 2023 un UK guidelines for secure AI system development. Le gouvernement du Canada, de son côté, a notamment publié un outil d’évaluation de l’incidence algorithmique (EIA). Il s’agit d’un questionnaire de 85 questions qui vise à évaluer l’impact d’un système de décision automatisé. Il a été créé en lien avec la Directive sur la prise de décisions automatisée du Conseil du Trésor, qui vise quant à elle à encadrer l’usage de l’IA par les services du gouvernement.
- L’Australie, qui a proposé dès 2028 un cadre éthique volontaire d’usage de l’IA, a décidé de poursuivre ses efforts de renforcement du cadre réglementaire entourant l’usage de l’IA. A ce titre, en janvier 2024, Ed Husic, ministre des Sciences et de l’Industrie, a publié un rapport détaillant un ensemble de recommandations. On y trouve par exemple la mise en place d’un organisme consultatif (en charge de collaborer avec des experts pour élaborer de nouvelles lois et définir les critères des systèmes d’IA à haut risque) ou l’exigence de transparence pour les fournisseurs.
- Le Japon, lui, a choisi une voie beaucoup moins contraignante en termes d’encadrement cyber des pratiques d’IA et favorise plutôt le partage des connaissances en à travers la valorisation des canaux d’échange alimentés par les développeurs et personnes en charge de déployer ces systèmes.
Et enfin, si vous souhaitez explorer le côté obscur de la force pour mieux protéger vos systèmes d’IA, il peut être intéressant d’étudier les outils de mise en œuvre d’attaques dédiés à l’IA. Ces derniers fournissent souvent des infos assez précises sur les nouvelles méthodes d’attaques, de détection et les vulnérabilités spécifiques. Par exemple, FraudGPT, vendu par abonnement 200 dollars par mois et jusqu’à 1 700 dollars par an (si ça vous intéresse…), cite dans son « catalogue de service” la création de code malveillant, de malwares indétectables, de pages web et de campagnes de phishing, l’identification de groupes de piratage, l’exploitation de fuites et vulnérabilités, etc.
Nous avons terminé le 1er article en constatant que l’IA s’installe durablement dans nos écosystèmes économiques, sociaux et informatiques. Et que le monde de la cyber n’est pas encore complètement prêt… Mais heureusement, les équipes data et SSI peuvent s’appuyer d’ores et déjà sur un panel de référentiels, guides et groupes de travail pour commencer dès maintenant à structurer leurs solutions de protection et réaction. De même, les fournisseurs de systèmes d’IA sont grandement incités, voire forcer suivant les pays, à contribuer à ce travail de sécurisation en proposant des solutions reposant notamment sur la qualité et la transparence. Hé oui, c’est basique, mais on ne protège bien que ce qu’on connaît bien….
D’ailleurs, en parlant de protection : maintenant que nous avons vu notamment les normes et standards de référence de sécurisation des systèmes d’IA ainsi que les lois et règlements applicables, comment, et avec qui, construire sa feuille de route sécurité des systèmes d’IA ? Par où commencer, et avec les contributions de quelles fonctions métier ? Et comment mettre à jour sa politique de sécurité, adapter ses processus métiers et sécurité, comment et vers quoi faire évoluer son plan de contrôle et son outillage sécurité ? C’est ce que je vous propose d’explorer ensemble dans la troisième, et avant-dernière, partie de cet article.
Troisième partie
Dans la 1ère partie de cet article sur l’IA & et la cyber, nous avons brossé un rapide portrait de cet écosystème. Dans la 2e partie, nous avons inventorié les principales catégories d’attaques, les risques associés et secteurs d’activité et applications les plus ciblés. Nous avons également passé en revue les principales lois et normes et travaux en court pour encadrer et sécuriser les pratiques de l’IA dans le monde.
Dans cette 3e et avant dernière partie je vous propose une liste d’actions à mener pour préparer votre organisation à sécuriser les technologies et usages IA, et notamment une mise à jour de votre processus d’analyse de risques ainsi que la sélection et le déploiement de mesures de protection et réaction spécifiques. La dernière partie sera consacrée à un aperçu du futur de l’IA pour la fonction SSI. Oui, l’IA peut aussi être l’ami du RSSI pas seulement son (nouveau) pire cauchemar ! 😉
On y va vraiment ?
Alors, oui évidemment, j’entends certains me dire qu’il est vraiment trop tôt pour se préoccuper de la protection des systèmes d’IA, que de toute façon les solutions ne sont pas encore matures. Et puis, au pire, il est toujours possible d’adopter la bonne vieille posture dite de l’autruche : affirmer haut et fort que l’IA n’entrera jamais au grand jamais dans votre organisation ! Comme le BYOD a été refoulé aux portes, ainsi que ses amis le cloud, le télétravail, l’usage des outils pros pour la vie perso, … Je continue ?
Penchons-nous sur les chiffres du baromètre 2024 de la cyber (Opinionway pour le CESIN) : “43% des répondants affirment que l’IA n’est pas officiellement utilisée en interne et son intégration s’apparente pour le moment à du Shadow IT..”. Petit exercice de pensée : si on enlève le terme “officiellement” de la phrase, comment ce pourcentage évoluerait selon vous ? Si vous avez encore du mal à vous persuader que cette posture du refus n’est peut-être pas la meilleure, allez demander à Samsung comment ils ont vécu début 2023 l’incident de sécurité lié au chargement par inadvertance dans ChatGPT de secrets d’affaires…
On peut alors tenter d’envisager la deuxième posture, dite de Végèce (selon toute vraisemblance) ou de Sun Tzu, et affirmez haut et fort que “qui veut la paix préparer la guerre”. De l’art de prévenir plutôt que guérir (ou mourir…). Et de préférence en adoptant une stratégie de guerre basée sur la “prise en tenaille”, c’est à dire en déployant des mesures qui partent du haut vers le bas et d’autres du bas vers le haut de l’organisation….
Le tableau ci-dessous synthétise un ensemble de préconisations sécurité, que je détaille dans les chapitres suivants.
| Étapes | Activités |
| Découverte | Connaître le terrain et l’étendue du “problème” : – Cartographies – Classification – Veille externe |
| Analyse & arbitrage | Personnaliser sa méthodologie et définir son niveau de tolérance |
| Sécurisation initiale | Les mesures de sécurité organisationnelle – Définissez votre gouvernance AI (et sécurité de l’AI !) – Sensibilisez – Formez – Adaptez les critères de recrutement Les mesures de sécurité fonctionnelle – Mettez à jour votre cadre documentaire – Révisez, et adaptez, vos contrats – ISP : barrez à gauche tout ! – Adaptez vos systèmes de détection, de réaction … et de communication ! – Mettez en place / renforcez votre dispositif d’audit et de contrôle continu Les mesures de sécurité technique – Back to basics – Sélectionnez vos schémas d’infras avec soin – Sécurisez vos modèles d’IA et leurs paramètres – Sécurisez l’exploitation (données et MLOps) – Continuez la veille technique ! |
C’est parti !
A) Connaître le terrain et l’étendue du “problème”
Il est vraiment essentiel de garder en tête qu’on ne protège bien que ce qu’on connait bien. A ce titre, il est vital de cartographier et classifier ses cas d’usage IA, aussi bien en production que dans des environnements de développement ou de “lab”.
- Cartographiez, cartographiez, cartographiez !!!
La data est l’essence de l’IA. Alors identifiez toutes vos bases de données, même les plus “anodines” (vous savez, celles qui tournent sur Excel dans un “coin de bureau” mais supportent en fait tout un morceau de prod.). On ne sait jamais …
Scannez aussi tous vos terminaux pour identifier les SI et les collaborateurs utilisant des technologies d’IA (sus au shadow IA !)
Identifiez aussi avec votre direction des achats tous les contrats pouvant pointer vers des prestations externalisées / sous-traitances de services d’IA. Vous pouvez compléter cette démarche d’inventaire de vos sources externes d’IA avec le support de votre service IT, en scannant tous les usages de solutions d’IA en mode SaaS
- Classifiez, classifiez, classifiez !!!
D’abord on inventorie (de manière exhaustive !) … et après on concentre ses efforts sur les composants les plus critiques en déterminant la sensibilité des éléments de son patrimoine IT et informationnel concernés (au fait, vous avez bien une matrice de classification de la sensibilité de vos données ? 😉).
En parallèle, il est grandement utile de mettre en place un système de notation de vos IA et construire sur cette base une “cartographie IA” de vos processus. Pour cela, vous pouvez par exemple vous inspirer du système d’indexation des systèmes d’IA développé par Ernst & Young, son “AI confidence index”, basé sur 5 critères : la protection de la confidentialité et la sécurité, les biais et l’équité, la fiabilité, la transparence et l’explicabilité.
Une fois vos systèmes d’IA inventoriés, un autre système de classification peut se faire pour identifier le niveau de maturité de votre organisation en termes de manipulation des IA. Car, au-delà du % d’utilisation des IA et avant même d’envisager les mesures de sécurité à déployer, il est important d’évaluer la maîtrise actuelle de votre organisation en termes de R&D, développement, mise en production et amélioration continue de ses systèmes d’IA. Pour cela, vous pouvez utiliser le Modèle de Maturité AIdu Gartner ou le COE’s AI Guide. Vous pourrez par exemple classer vos solutions d’IA en trois catégories : “expérimentation”, “développement actif” et “utilisation en production”.
- Identifiez les exigences légales et réglementaires applicables
En parallèle de tous les travaux d’inventaire et classification de vos cas d’usage IA, il est vital de travailler avec votre département conformité et/ou juridique pour identifier l’ensemble des lois, règlementations et normes applicables à votre secteur et lieux d’activité, et des types d’IA utilisées et mettre en place un processus de veille en continu.
En combinant les résultats des travaux de cartographie et classification et les exigences légales et réglementaires applicables, vous serez plus à même de passer à l’étape suivante, à savoir l’analyse de risque !
B) Personnaliser sa méthodologie d’analyses de risque et définir son niveau de tolérance
Alors, pour vous mettre bien à l’aise, Apostol Vassilev, informaticien au NIST et l’un des auteurs du rapport de cet institut sur les menaces liées à l’IA (“Adversarial machine learning: a taxonomy and terminology of attacks and litigations (NIST. AI. 100-2)”) : “Nous fournissons une vue d’ensemble des techniques et méthodologies d’attaque qui prennent en compte tous les types de systèmes d’IA (…] nous décrivons également les stratégies d’atténuation actuelles décrites dans la littérature, mais ces défenses disponibles manquent actuellement de garanties solides quant à leur capacité à atténuer pleinement les risques. Nous encourageons la communauté à proposer de meilleures solutions. (…) La sécurisation des algorithmes d’IA pose des problèmes théoriques qui n’ont tout simplement pas encore été résolus. Si quelqu’un dit le contraire, c’est qu’il vend de l’huile de serpent”.
À garder cet avertissement en tête (certes, conjoncturel et temporaire) dans les activités d’analyse de risques des usages de l’IA.
Alors, pour commencer, rapide crash course pour rappeler à tous les base d’une démarche d’analyse de risque : la toute première étape pour mitiger les risques liés à l’usage de l’IA consistent en effet à évaluer son niveau d’exposition, définir son niveau de risque puis d’identifier les mesures de protection, détection et réaction les plus efficientes et prioritaires.
Le terme de risque peut être décrit en combinant les termes suivants :
“Une personne / exploite / une vulnérabilité, plus ou moins facilement, / créant ainsi une menace / sur une ressource / à travers la réalisation d’une action qualifiée d’événement redouté par l’organisation cible / car ayant un impact négatif plus ou moins grave / sur ladite ressource”
Les impacts sont assez classiques : vol d’informations sur le modèle ou les données qu’il manipule, perte d’intégrité du modèle ou des résultats produits, perte de disponibilité du SI. Rien de bien différents des impacts des systèmes non IA.
En revanche, d’autres termes de cette définition peuvent être spécifiques aux attaques des systèmes d’IA. Il me semble donc pertinent de personnaliser le processus d’évaluation, traitement et d’acceptation des risques liés à l’usage de l’IA pour faciliter le travail des acteurs des travaux d’analyses de risques (propriétaires de la ressource, développeurs, référents conformité, responsables data, référent sécurité, etc.)
Par exemples :
- Une personne : on peut cibler plutôt les sources humaines, à prédominance “externe” et réalisant une action malicieuse intentionnelle (plutôt qu’accidentelle),
- Vulnérabilités et faisabilité : pendant la phase d’apprentissage ou d’entrainement les attaques les plus impactantes, et donc visées en priorité, seront basées sur l’altération du processus d’apprentissage par la fourniture de données corrompues. Si on se réfère à la littérature sur le sujet, il s’agit toutefois d’attaques encore relativement complexes à mener. Pendant la phase d’inférence ou de production, la tendance sera plutôt à fournir des données erronées en entrée, qui représente une attaque avec un impact moindre mais plus facile à réaliser.
Les référentiels de risques utilisés en interne peuvent aussi être adaptés en fonction des cas d’usage à étudier. Par exemple l’usage des LLM et de l’IA générative sont largement contextuels et dépendent en grande partie des cas d’usages spécifiques à chaque secteur d’activité.
Il est à noter également qu’une attention particulièrement doit être portée à la phase d’évaluation des risques résiduels. Les systèmes d’IA sont difficiles à protéger du fait de leur construction statistique, qui les rend par nature imparfaits et prédisposés à un comportement imprévisible. Ceci peut induire une confiance excessive dans les résultats produits et donc faciliter l’obfuscation d’attaques.
D’ailleurs, la personnalisation du processus d’analyse de risques doit se réaliser avec une actualisation du niveau de tolérance aux risques spécifiques liés à l’IA, que ce soit par la DG que par chaque Métier et Fonction support susceptible d’utiliser ces systèmes.
Maintenant que nous avons vu comment évaluer le niveau de risque face aux cas d’usage IA, la prochaine étape est d’évaluer le mode de traitement du risque (acceptation, évitement, transfert/partage ou réduction).
Attention, premier disclaimer !
Comme à chaque fois, les niveaux de tolérance différent d’une entité à une autre et les solutions de sécurité des uns ne sont pas forcément les plus adaptées pour d’autres. One size DOES NOT fit all. Tout simplement parce que les organisations n’utilisent pas toutes les mêmes technologies d’IA, et certaines technologies sont par défaut plus avancées et sécurisées que d’autres. De mêmes elles ne sont pas utilisées dans les mêmes conditions et enfin les fonctions sécurité ne disposent pas toute du même niveau de maturité ni des mêmes capacités d’action.
C’est pourquoi je vous propose ci-dessous un peu une liste à la Prévert de préconisations de sécurité. A vous d’y piocher ce qui fait le plus de sens au regard des résultats de vos analyses de risques, des exigences externes auxquelles vous êtes soumis, de la charge disponible de vos équipes, du niveau de maturité de votre organisation (tant sur le plan sécurité qu’en termes de gestion de la data et des SI) et du pourcentage de déploiement des mesures de sécurité les plus primordiales.
Mais dans tous les cas, il me semble primordial d’y penser dès maintenant, même si l’usage de l’IA est encore embryonnaire dans votre organisation, ou inexistant (et on ne sait jamais, on a eu le shadow IT, le shadow cloud ; qui peut être certain d’être à l’abri du shadow IA ?).
Attention, deuxième disclaimer !
Le concept du big bang c’est peut-être parfait pour le cosmos mais c’est rarement une solution gagnante dans le mode de l’IT et des organisations.
C’est pourquoi, quelles que soient les mesures de sécurité que vous allez déployer, définissez toujours une approche concentrique et graduelle : commencez par un sous-ensemble de mesures, sur un périmètre pilote, puis réussissez / échouez mais surtout apprenez de vos actions ! Puis étendez peu à peu votre déploiement sécurité à d’autres mesures et d’autres périmètres de l’organisation. “Step by step”, “Qui va piano va sano”, adoptez le mantra que vous voudrez mais surtout allez y pro-gres-si-ve-ment ! Rien de pire qu’un déploiement non contrôlé qui créerait plus de vulnérabilités qu’il n’en résoudrait ou soulèverait un tel rejet qu’il rendrait impossible la mise en place de toute nouvelle mesure de protection ou d’encadrement.
C) Déployer des mesures de sécurité organisationnelle
- Définissez votre gouvernance AI (et sécurité de l’AI !)
Il est essentiel d’assigner des responsabilités sur la propriété et la saine gestion des modèles d’IA et des données utilisées, ainsi que sur la gouvernance des risques associés.
A ce titre, il pourrait être pertinent de créer une fonction centrale chargée d’étudier, affiner et organiser les usages de l’IA et accompagner les réflexions sur un cadre responsable d’utilisation ainsi que les principes et le rythme de déploiement d’une stratégie cyber.
En complément, il conviendrait de renforcer la gouvernance de la donnée : nommer des responsables métier en charge de nettoyer, dupliquer, “certifier” et définir / contrôler l’accès à ces données, selon des normes internes standards et mises à jour pour intégrer des critères de classification et traitement propres aux cas d’usage IA. Que vous soyez dans une logique de gestion de la donnée en mode “datamesh” ou datalake centralisé, la définition des règles de gouvernance de la donnée permet non seulement un meilleur inventaire du périmètre de couverture de l’IA mais aussi une fiabilisation des entrants, une gestion facilitée des droits d’accès et de leur re-certification, des actions de traçabilité des opérations et d’observabilité des données. Autant d’éléments indispensables pour répondre aux exigences légales et réglementaires en termes de transparence et de maîtrise des systèmes d’IA.
Et si possible, identifiez vos (cyber) champions de l’IA, capables d’accompagner les autres collaborateurs dans les usages des systèmes d’IA spécifiques à votre organisation et dans l’identification des règles de sécurité les plus pertinentes à votre contexte.
- Sensibilisez, sensibilisez, sensibilisez vos utilisateurs (ou l’art de rappeler les basiques pour bien qu’ils s’imprègnent)
Il est important de sensibiliser chaque catégorie d’utilisateurs (usagers finaux, développeurs, data scientists et data engineers, responsables de la gestion des données, responsables marketing, référents Métiers…) aux risques et impacts associés à l’usage (et développement) de systèmes d’IA : les risques de vol de données, de pertes d’indisponibilité des SI mais aussi les impacts en termes de sanctions juridiques, impacts financiers et dommages réputationnels que l’organisation, ou eux-mêmes!, peut subir en cas d’usage inapproprié.
Les exemples d’incidents ne manquant malheureusement pas, servez-vous en à volonté pour rendre vos messages les plus concrets et impactant possibles. Mais surtout pensez à adapter vos messages aux usages réels de votre organisation et en utilisant des référents internes. Par exemple, quoi de plus parlant qu’un message de sensibilisation commençant par un deep fake du PDG de l’entreprise ou du responsable de l’entité du collaborateur public (avec leur accord préalable 😉)
En partenariat avec le DPO, montez des supports de sensibilisation sur les deux grands enjeux de l’IA face au GDPR : la complexité et l’opacité. Le GDPR implique que les processus de traitement des données soient clairs et compréhensibles. Or beaucoup de systèmes d’IA fonctionnent en mode “boite noire”. De plus, le GDPR impose que les individus soient assurés que les décisions prises à leur encontre ne reposent pas uniquement sur un processus automatisé. Comment garantir que les résultats fournis par les IA seront intégrés comme un des éléments d’évaluation parmi d’autres et non pas comme la seule source de décision ?
Comme chaque fois l’objectif ultime est de faire en sorte que vos collaborateurs se posent les bonnes questions avant de déployer ou d’utiliser une techno d’IA… de façon… disons … inappropriée….
Et gérez le changement ! Non seulement il convient de sensibiliser les équipes aux nouvelles règles et usages liés à l’usage de l’AI, mais aussi de les accompagner d’un point de vue opérationnel dans ces changements. Car les erreurs viennent autant d’un manque de sensibilisation que de préparation.
- Formez !
La sensibilisation, c’est bien. Mais la formation pour les publics en charge des activités de développement, d’exploitation et maintenance ou de contrôles des systèmes d’IA, c’est mieux !
Les publics cibles à prioriser sont donc notamment les équipes sécurité, IT (développeurs, data scientists, data engineers, (cyber) champions IA), les DPO, des référents “conformité/gestion des risques”. Ce programme, à construire au maximum sur base de cas d’usage internes réels ou a minima du même secteur d’activité, pourrait être constitué d’un tronc commun à l’ensemble de ces praticiens et traitant des enjeux techniques, réglementaires et sécurité (attaques, risques et protection) ; avec pourquoi pas un rappel sur la méthode d’analyses de risques en vigueur dans l’organisation et quelques éléments sur les bases de l’hygiène sécurité (car pourquoi s’embêter à attaquer un système d’IA si le SI support est une passoire ambulante ?).
Ce tronc commun pourrait être complété par des sessions dédiées aux spécificités IA de chaque métier ainsi que des temps de partage d’expérience entre tous, pour que chacun comprenne les cas d’usages en cours mais aussi les enjeux, questionnements et difficultés des uns et des autres.
Il serait aussi intéressant d’évaluer la pertinence d’intégrer dans ces parcours des étapes de certification, notamment à la norme ISO 42001 sur le système de management des systèmes d’IA.
- Adapter les critères de recrutement
Pour les départements régaliens et de contrôles, il serait opportun de commencer un échange avec les départements RH pour évaluer quels nouveaux critères inclure dans les recherches pour s’orienter vers des candidats disposant déjà de connaissances sur les lois, référentiels et standards existants. Pour le moment, le pourcentage de collaborateurs disposant de ces expertises est faible, mais la tendance va aller croissante, en parallèle du développement des pratiques dans les organisations et de la mise à jour des parcours de formation.
À titre d’exemple, Google a annoncé récemment toute une série de mesures en faveur d’une meilleure prise en compte de la cyber sécurité dans le domaine de l’IA. Il a notamment indiqué vouloir augmenter de 15 millions le fond de son programme de séminaires cyber google.org pour couvrir l’intégralité du territoire européen. Ce programme vise notamment à aider les universités à former la prochaine génération d’experts cyber en IA.
D) Déployer des mesures de sécurité fonctionnelle
- Mettez à jour votre cadre documentaire
Et si vous commenciez en faisant travailler votre DG ? Il s’agit, en parallèle et complément du travail visant à définir le seuil de tolérance de l’organisation en termes d’IA, de définir le cadre d’un usage responsable de l’IA au sein de l’organisation, au regard des risques de réputation, financiers et juridiques associés (la combinaison gagnante des trois chevaliers de l’apocalypse capables pour faire réagir n’importe quelle DG normalement).
Sur cette base il devient possible de décliner un politique d’usage de l’IA et/ou d’ajouter un chapitre dédié à l’IA aux politiques de sécurité des SI, de gestion des données et de maîtrise des risques. Dans ces documents seront définis la gouvernance cyber de l’IA ainsi que le cadre et les règles d’usage fonctionnelles, techniques et contractuelles en fonction notamment :
- De la nature de l’architecture du système (strictement interne ou ouvert vers l’externe, de développement ou de prod…) et des pratiques de développement /optimisation (composants entièrement construit en interne, ou reposant également sur de composants de fournisseurs tiers ou de briques open source)
- Du nombre et du type d’acteurs impliqués (IT ou non, utilisateurs et fournisseurs internes ou externes, appartenant à une catégorie sensible ou à risque, comme les mineurs, …)
- De la nature des données utilisées (publiques, sensibles, voire personnelles, et anonymisées/pseudo anonymisées ou pas, à durée de conservation limitée ou pas/peu, issues de bases interne ou de sources externes d’enrichissement des données comme dans le cas des RAG (Retrieval Augmented Generation) du niveau d’encadrement légal et réglementaires des cas d’usage
- Du niveau de maturité et des capacités de transparence des processus et solutions déployées
- ….
À ce socle de politiques pourrait être ajoutée une charte d’utilisation préconisant les bons usages de l’IA (histoire aussi de rattraper les réfractaires à la lecture des politiques, parait qu’il y en a encore…).
Il conviendra également de mettre à jour aussi les procédures fonctionnelles et opérationnelles, comme (et au hasard…) celles sur l’Intégration de la Sécurité dans les Projets (patience, on en reparle un peu plus loin…)
Last but not least, mettez à jour votre dispositif de gestion des risques pour cataloguer de façon explicite et suivre dans le temps de façon continu, très régulière et spécifique les usages et les risques associés à l’IA, surtout dans ce contexte actuel en mode far-west où les outils ne sont pas encore fiables, les concepteurs et utilisateurs pas assez sensibilisés et formés et les pirates toujours autant (voire plus!) aux aguets
Un dernier point, qui me parait essentiel : pour que l’ensemble de ce cadre documentaire sécurité soit pertinent et largement partagé au sein de l’organisation il est in-dis-pen-sa-ble qu’il soit construit en partenariat avec l’ensemble des métiers et autres fonctions supports impliqués sur les sujets d’IA, à savoir au moins des référents DSI, le DPO, le DRH, le “Data officier”, un référent juridique, marketing & com, de l’Innovation et de la relation Client. Profitons du sujet de l’IA pour commencer à faire sortir la sécurité de sa tour d’ivoire et échanger avec toutes les parties prenantes de l’organisation pour formaliser son cadre régalien.
- Révisez, et adaptez, vos contrats
Pour vous protéger du risque induit par l’usage de solutions d’IA fournies par des tiers, il est important d’être vigilant avec les termes des contrats de service signés avec vos fournisseurs, surtout s’il s’agit de contrats génériques. Par exemple, pensez à vérifier l’existence, dans la section “privacy” des contrats, les informations précisant si les systèmes d’IA ont été développés entièrement en interne par votre fournisseur ou s’il s’agit d’une solution en sous-traitance ou intégrant des modules externes (et remerciez le RGPD de l’obligation de cette faire figurer cette mention !).
Prenez soin également de bien relire toutes les mises à jour contractuelles “proposées » par vos fournisseurs au fil de l’eau.
On voit à travers ça que, d’une manière plus globale, il est important de commencer à initialiser les échanges avec vos Directions des Achats et Juridiques pour adapter et renforcer vos processus et dispositifs de gestion des risques des tierces parties.
- ISP : barrez à gauche tout !
Dans une approche “shift left”, la sécurité doit être prise en compte dès les premières étapes du projet. On l’a dit, on le dit et on le re-dira encore et encore (et même pas déso ! 😉). Et cela est d’autant plus vrai avec les projets d’IA.
En complément de l’adaptation des référentiels d’analyse de risques (comme vu précédemment), il s’agit notamment :
- d’étendre le périmètre de l’ISP (Intégration de la Sécurité dans les Projets) aux activités portées en amont par de recherche, d’analyse et de design portées par les data scientists autant que les data engineers
- de définir un cycle de développement (en mode agile ou pas) spécifique aux projets d’IA puis de mettre à jour en conséquence le contenu et positionnement des jalons sécurité tout au long du projet
- corolaire important, profitez-en pour renforcer les bonnes pratiques en termes de documentation de toutes vos étapes du projet, décisions : architecture, infrastructures (physiques et logiques), données en entrée et traitements. Les exigences de transparence et de maîtrise des systèmes d’IA sont telles (notamment dans l’IA Act et le GDPR) que cette activité s’avère définitivement essentielle !
- d’étoffer votre boite à outils des solutions de “privacy by design” : d’un point de vue fonctionnel, cela passe par une sensibilisation accrue des développeurs, data scientists et data engineers sur le sujet ; mais aussi d’un point de vue technique par le déploiement de zones d’environnement de confiance, un meilleur accès et une plus grande utilisation des infrastructures de chiffrement, le déploiement d’outils de tokenisation, de méthodes d’anonymisation, etc.
- Adaptez vos systèmes de détection, de réaction … et de communication ! (amis du SOC et de la com, entendez-vous le bruit sourd des IA qu’on déchaine…)
Il convient d’adapter d’une part les outils de collecte et d’analyse des données produites par les environnements d’IA et les composants tiers de leur écosystème, mais aussi les schémas de réactions techniques en interne et de communication vers l’externe. Etant donné la sensibilité du grand public aux usages inappropriés de l’IA, une organisation ne peut se permettre de communiquer de la même façon sur une attaque par ransomware (même si on est déjà dans un niveau d’alerte très élevé) et un incident de sécurité d’un système d’IA ayant entrainé des conséquences physiques pour des individus…
- Mettez en place / renforcez votre dispositif d’audit et de contrôle continu
Parmi tous les fondamentaux d’un système de management, celui lié à la création et au maintien des procédures et contrôles est absolument essentiel dans le domaine de l’IA, en raison à la foi du manque de maturité de nombreux systèmes utilisés, couplée à une courbe d’innovation ascensionnelle et des exigences règlementaire de transparence et de maitrise très importantes.
Nous avons vu plus haut dans cet article qu’il était plus qu’opportun d’adapter le processus d’analyse et d’acceptation des risques aux usages de l’IA, afin que les responsables de ces activités puissent comprendre plus facilement la nature et l’impact des risques que ces systèmes peuvent potentiellement faire courir à leur organisation et.ou à leurs utilisateurs. Dans la continuité, il convient aussi d’adapter et personnaliser le dispositif de contrôles. A titre d’exemples, on peut citer la mise en place de contrôles sur :
- La minimisation des données et des champs associés
- La détection d’entrées non conforme ou contradictoires
- L’anonymisation de ces mêmes données
- Le respect des bonnes pratiques en termes de gestion du cycle de vie des données (incluant la maitrise des durées de rétention)
- La prise en compte des critères de conception qualifiant des modèles résistants à l’évasion
- La vérification de comportements spécifiques non désirés lors de l’entraînement puis de l’usage des modèles en production ainsi qu’après leur mise à jour
- etc…
Il est ainsi crucial de surveiller l’usage des modèles et de stocker des métriques clés comme les données en entrée, la date et l’heure, et les logs associés des utilisateurs, notamment pour optimiser le processus de traçabilité, de surveillance et de gestion des incidents.
E) Les mesure de sécurité technique
- Back to basics (vous ne l’aviez pas vu venir celle-là, hein ?! 😉)
Inutile de chercher à sécuriser globalement un système d’IA si les données sensibles qu’il manipule sont stockées dans une base de données dont l’accès est possible à partir d’un couple “compte à privilège / mot de passe” de type “admin / admin” (au hasard…) ou sur un SI sous-jacent qui attend ses mises à jour depuis 6 mois…. Commencer par fermer les portes de sécurité les plus évidentes est bien plus efficace pour se protéger des attaquants que de déployer des solutions complexes et encore mal maitrisées de protection spécifique contre les attaques visant le cœur même des IA. Et pour un ROI plus élevé !
Alors pensez à mettre à jour vos systèmes, mais aussi déployer des mécanismes robustes d’attribution et de recertification des accès aux espaces de stockage des données, des modèles et du code source. En parlant de code source, peut-être une révision avec vos développeurs des bonnes pratiques de sécurisation du code et de protection des données personnelles ? Le guide RGPD du développeur produit par la CNIL est une mise d’informations à ce sujet ! Et, en complément, assurez-vous que vos outils d’audit de code tournent à plein régime sur les repos de code pour vos systèmes d’IA
- Sélectionnez vos schémas d’infras avec soin
Il est important de choisir la bonne infrastructure d’IA en fonction du type de problème qu’elle doit résoudre et d’identifier les SI spécifiquement adapter pour y répondre. Car chaque scénario d’infra présentera des avantages et des limites d’un point de vue sécurité. Par exemple, il est important de prendre le temps d’évaluer les opportunités et les risques à favoriser l’usage d’un écosystème d’IA reposant principalement sur l’open source ou des systèmes propriétaires, ou à ouvrir vos infras vers l’extérieur pour utiliser des fonctionnalités de RAG afin d’enrichir les résultats produits ou à se concentrer sur des données stockées en internes.
- Sécurisez vos modèles d’IA et leurs paramètres
Tout comme il convient de construire avec précaution les architectures supports à vos systèmes d’IA, il convient d’être vigilant sur les paramètres de sécurité des modèles qui seront déployés.
- Assurez-vous que la source de votre modèle est fiable, que vous maitrisez les éléments qui le composent, que vous déployez la dernière version disponible et que son processus d’évolution est connu, transparent et documenté
- Pensez à définir les critères permettant de choisir des modèles résistants à l’évasion de données
- Assurez-vous de restreindre l’accès aux informations relatives notamment à :
- La distribution des données ayant servi à l’apprentissage du modèle
- L’architecture du modèle
- L’algorithme d’optimisation utilisé
- Le poids et les biais du réseau de neurones
- …
- Sécurisez l’exploitation (données et MLOps)
La sécurité des données exploitées est clé. Cet aspect est déjà mentionné plus haut, dans la partie relative aux mesures fonctionnelles, mais il est tellement crucial qu’il me semble indispensable de l’évoquer à nouveau ici :
- Vérifiez la qualité des données en entrée. Viennent-elles d’une golden source, de sites web non maîtrisés, d’échanges avec des utilisateurs ? Afin de protéger la période initiale d’apprentissage ou celle d’amélioration continue, il est indispensable de protéger vos systèmes de toute ingestion de données non intègres, entraînant une corruption intentionnelle ou non.
- Définissez vos attentes quant aux résultats produits et assurez un suivi. La maîtrise des données en sortie (nature et intégrité des résultats) est tout aussi importante que celle des données en entrée, et peut représenter un indice critique d’une possible corruption.Evaluez aussi la pertinence en fonction des cas d’usage de déployer des solutions de tokenisation, de masquage et de chiffrement des données, d’encodage des résultats des modèles, notamment pour vous protéger des attaques d’injection traditionnelle ; mais aussi de désensibilisation des données lorsque possible
- Evaluez la possibilité d’incorporer des mesures de protection des données directement dans les opérations réalisées par les IA, par exemple :
- La “differential privacy” (capacité à apprendre de tendances générales plutôt que d’informations personnelles d’individus spécifiques)
- Le “federated learning” (entraînement des modèles sur des données décentralisées – entraînement de l’algorithme via de multiples sessions indépendantes, chacune disposant d’un seul jeu de données)
- Ou encore en établissant des bonnes pratiques d’usage des services utilisateurs, par exemple de collecter que les données strictement nécessaires pour chaque cas d’entraînement et d’usage
- Sécurisez aussi le transport et le stockage des paramètres de vos modèles, pour limiter les risques de fuite de données, en utilisant des solutions de contrôle d’accès, de chiffrement et de limitation de la durée de rétention des prompts injectés.
- Et bien sûr, mettez en place des mécanismes pour vous protéger des attaques par injection dans le prompt, via notamment un encadrement des accès du LLM aux systèmes en backend ou la ségrégation du traitement des données issues de contenu externe de celles issues des prompts des utilisateurs.
Au-delà de la sécurité des données exploitées, il convient aussi de s’assurer de la sécurité des opérations de MLOps elles-mêmes :
- Mettre en place un processus de gestion et documentation des changements apportés aux modèles d’IA et aux données
- Utiliser des chaînes CI/CD automatisées et standardisées et des modules packagés (containers), afin de garantir la (bonne) reproductibilité, de limiter les erreurs venant des interventions humaines et maitriser les potentielles migrations d’une infrastructure à une autre.
- Garder une trace du parcours de développement de vos modèles d’IA, pour comprendre ses évolutions et pouvoir mieux les suivre et les expliquer
Continuez la veille technique !
Et comme il vous restera sûrement encore un peu de temps 😉, pourquoi ne pas en consacrer une partie à assurer une veille des outils dédiés spécifiquement à la maîtrise des risques liés à l’usage de l’IA. Comme rappelé plusieurs fois dans cette série d’articles, nous faisons face à des technologies encore mal comprises et maîtrisées, parfois peu matures. Mais qui évoluent très vite ! Et il en est heureusement de même pour les solutions destinées à les sécuriser. Pensez par exemple à regarder du côté des outils de détection des systèmes d’AI, ou encore les “natural language web firewalls”, qui commencent à composer les plateformes de sécurisation des systèmes d’IA (comme annoncé par exemple par CloudFlare ou Robust Intelligence).
Conclusion
Cet article s’est concentré sur l’inventaire des risques, des normes et solutions de protection des outils d’IA actuels. Mais c’est un domaine en évolution constante. Selon Yann LeCun, directeur de la recherche en IA de Meta, “l’IA générative n’est qu’un détour sans lendemain, dans une histoire technologique vouée à se prolonger vers des assistants plus intelligents, capables de percevoir l’environnement”. L’avenir de l’IA est pour lui l’AMI (Advanced Machine Intelligence), qui verrait notamment les systèmes d’IA « comprendre la réalité sous-jacente aux concepts qu’ils manipulent”. Ces systèmes reposeraient sur une architecture contrôlée par objectifs (Objective-driven AI). Cette architecture nécessiterait que le système dispose de critères d’efficience (comment minimiser les actions à réaliser pour atteindre les objectifs visés) mais aussi de sécurité (quels garde-fous avoir pour éviter tout détournement à des fins malveillante). Encore tout un domaine de l’IA à comprendre, standardiser et surveiller. Rassurez-vous, pas avant demain (mais l’avenir se préparer aujourd’hui dans les labos !).
Allez, je vais quand même veux terminer par une note positive, et qui encore plus à hauteur que l’IA prendra une part croissante dans nos organisations. Selon moi, l’IA peut être le facteur accélérateur qui permettra de transformer le CISO en BISO. L’IA s’applique à tout ce qui manipule des données. Et dans nos organisations et usages du quotidien, tout manipule des données. Ainsi, la diffusion de l’IA dans toutes les strates de l’organisation, et en corolaire la diffusion croissante du risque sur la donnée à travers l’organisation aussi jusque dans le quotidien de tous les acteurs, va renforcer le besoin combler le fossé encore présent entre sécurité des technologies et objectif métier. Et le besoin d’une fonction (et d’une femme / homme leader) capable de transposer les risques techniques dans un narratif opérationnels, financiers et stratégiques permettant aux opérationnels métiers et à la DG de prendre les bonnes décisions en tout connaissance de choses voire en faisant de la bonne gestion de la sécurité un élément clé du discours renforçant la confiance des clients, et donc l’avantage concurrentielle, dans un monde où le public est sensibilisé à ces enjeux.
Nous voilà à la fin de l’inventaire des mesures de sécurité organisationnelles, fonctionnelles et techniques qui peuvent être mises en œuvre pour préparer votre organisation à sécuriser les environnements d’IA. Encore une fois, il est important de garder en tête que cette liste est à utiliser comme un inventaire “à la carte” plutôt qu’un menu imposé : il convient de choisir les mesures les plus adaptées à ses cas d’usage, à sa maturité It et cyber et aux ressources dont on dispose. Puis de procéder à un déploiement séquentiel, concentrique, et toujours avec l’appui et la contribution des différentes parties prenantes concernées au sein de l’organisation, du développeur au juriste en passant par le DPO et le data scientist.
Dans la dernière partie qui vient clore cette série, nous nous concentrerons sur l’aspect peut-être le plus réjouissant (non, non, ne boudons pas notre plaisir !), à savoir l’apport que l’IA peut avoir pour améliorer, et peut-être réorienter, la fonction SSI.
Quatrième partie
Nous nous retrouvons pour aborder ensemble la 4e et dernière partie de cette série d’articles sur l’IA et la sécurité.
Pour commencer, nous avons évoqué l’historique et l’écosystème de l’IA (partie 1) . Puis, nous avons passé en revue les principales catégories d’attaques, risques associés, secteurs d’activité et applications les plus ciblés ainsi que les lois, normes et travaux en cours pour encadrer et sécuriser les pratiques de l’IA (partie 2). Tout naturellement, nous avons enchainé avec un aperçu des mesures de protection organisationnelles, fonctionnelles et techniques à mettre en œuvre sécuriser les technologies et usages IA au sein d’un organisation (partie 3).
Je vous ai donc gardé le meilleur, le plus enthousiasmant, pour la fin ! Dans cette dernière partie, nous allons maintenant discuter des potentiels apports de l’IA pour la fonction SSI et comment le RSSI peut en bénéficier pour faire évoluer son rôle de façon positive. Une partie des éléments que je développe ci-dessous est issue de la table ronde à laquelle j’ai participé le 28 mars dans le cadre de l’édition 2024 du forum InCyber : “Vers une IA « super oracle en cybersécurité » : quel rôle pour le RSSI demain ?
Les apports de l’IA à la cyber
Dans le monde de la cyber sécurité, il est assez fréquent d’envisager l’IA uniquement comme une source de risques négatifs. Mais si on prend 5 minutes pour relire la définition du terme “risque” selon la norme ISO 9001 on y voit qu’un risque est décrit comme l’effet d’une incertitude sur l’atteinte des objectifs d’une entreprise, qui se traduit par un écart positif ou négatif, par rapport à une attente, quelle que soit sa nature.
Un risque peut donc représenter un effet positif ! Les bonnes nouvelles n’arrivant pas tous les jours, je suis d’avis qu’il est plus que nécessaire de prendre un moment pour évaluer en quoi l’IA peut, et pourra, améliorer l’action préventive, détective et réactive de la SSI et faire évoluer au mieux le rôle du RSSI.
C’est en tout cas un sujet sur lequel s’est penché Sanjiv Kumar, directeur de recherche de Google, pour qui l’IA peut permettre de construire des outils de défense venant en support en premier lieu aux utilisateurs finaux : “Large deep-tech corporations have a big constructive role to play in creating the required tools and services (…) Such offerings can help business and tech users, especially the small defenders, guard better against many of the new Ai-generated cyberattacks”.
Car, si on prend un pas de recul, on voit vite que quand on parle IA, on parle en fait de traitements visant à gérer et analyser de grands volumes de données, d’en extraire des informations pertinentes et utilisables afin de soutenir une prise de décision basée sur des éléments objectifs. Or, ce type de traitements est au cœur même de la fonction sécurité. C’est pourquoi je suis convaincue que de nombreux cas d’usage vont émerger dans les prochaines années pour optimiser le travail non seulement du RSSI mais aussi de tous les acteurs impliqués de façon plus générale dans la maitrise des risques cyber (risk managers, propriétaires de processus Métier, développeurs, équipes SOC…).
Parmi les cas d’usage que l’on peut citer :
- L’amélioration de la qualité des cartographies d’analyse des risques. Selon le panorama 2023 de la gestion des risques produit par l’AMRAE, l’IA serait un formidable outil pour améliorer la gestion des risques, et ce à plusieurs niveaux : amélioration de la compréhension des risques et aide à la décision pour les mesures d’atténuation, détection des risques émergents, surveillance des contrôles, automatisation des tâches allouées aux équipes de gestion des risques, comme la collecte de données, la surveillance des contrôles, l’amélioration de la communication et de la sensibilisation, le traitement des milliers de de lignes de commentaires rédigés en permanence par les risk managers à propos de pièces justificatives…“Les méthodes traditionnelles nécessitent des investissements lourds avec des coûts élevés (…) l’IA générative permet d’automatiser rapidement des analyses structurées(…) L’IA peut aussi être utilisée pour proposer de revoir une recommandation d’audit en cohérence avec des pratiques réelles du marché ou une expérience antérieure. Elle joue les copilotes, en quelque sorte. “
- L’amélioration de l’aide à la décision pour la gestion des vulnérabilités : grâce à l’IA, nous pourrions acquérir une meilleure connaissance de notre environnement, à la fois interne et externe (ex. : IA, dis-moi quelles sont les acteurs malveillants les plus actifs en ce moment ? Quels sont les signes de la présence de backdoors sur mon périmètre IT ?).
- La génération et le contrôle du code : via des systèmes d’IA génératives spécifiquement entrainées à éviter et/ou identifier des failles de développement ou patterns favorables à l’exploitation, un temps précieux serait gagné lors des phases de création et de contrôle de code. Et si la détection des erreurs est réalisée de manière à attirer l’attention du développeur et de co-définir les pistes d’évolution du code, cela représente un gain indéniable en termes de responsabilisation et sensibilisation.
- La détection de comportements inhabituels, incohérents ou dangereux et l’automatisation du déclenchement de certaines alertes : des solutions s’appuyant à la fois sur les capacités cloud (ex. : facilité de déploiement) et boostée à l’IA pourraient être plus efficaces pour corréler des signaux faibles et ainsi plus rapide à détecter et prévenir les menaces. On parle ainsi d’AIOps, un terme qui désigne l’utilisation de technologies d’IA pour notamment collecter et analyser en temps réel des données provenant des outils de supervision, afin de détecter des anomalies n’ayant pas été identifiées par ces mêmes outils et ainsi générer plus rapidement des alertes plus pertinentes. De même, des sondes de supervision des réseaux (IDS/IPS) ou terminaux (EDR) intègrent déjà des technologies d’IA, en complément de leur moteur de détection par signature afin d’améliorer leur capacité à reconnaitre un programme malveillant.
Autre aspect intéressant car complémentaire, l’AIOps permet également un suivi plus efficace des tendances et une meilleure compréhension des comportements des utilisateurs, ce qui peut être utile pour anticiper les besoins futurs de l’infrastructure informatique.
Si on termine par un angle plus métier, toujours selon le panorama de gestion des risques de l’AMRAE, les outils d’IA permettraient d’améliorer largement les activités de détection de la fraude : « Des bots alimentés par des data financières vont chercher les informations spécifiquement nécessaires et le système établit des corrélations complexes entre elles, ce que les outils classiques ne savent pas faire. La solution détecte ainsi des schémas suspicieux, de blanchiment par exemple, et les signale au superviseur qui peut ainsi s’adapter. » Dans le même ordre d’idée, des systèmes de surveillance en continu boosté à l’IA seraient en mesure de suivre de façon plus efficace les facteurs de risques en temps réel dans les ERP actuels et de déclencher des alertes en cas de risques inhabituels, de défaut de contrôle ou de patterns anormaux.
- L’optimisation et la personnalisation du contenu des campagnes de sensibilisation ainsi que la manière dont elles seront menées. Pour commencer, quoi de plus beau qu’un bot capable de répondre à la volée à toutes les questions des utilisateurs sur les règles de sécurité en vigueur dans l’organisation, les bonnes attitudes à adopter en cas de détection d’un problème potentiel, les personnes contact à solliciter à la suite d’un incident ? Et au-delà, que pensez-vous de campagnes de sensibilisation déclenchée automatiquement et en temps réel sur la base d’une action sensible et/ou dangereuse effectuée par un utilisateur, ou dont le contenu serait plus créatif et adapté à chaque sous-groupe de publics cibles, en fonction des activités Métier vraiment réalisées au quotidien ?
- La mise en place d’une Contrôl Tower sécurité : aaah vous l’imaginez ce futur (proche!!!) où le/la responsable sécurité, arrivera chaque matin à son bureau et pourra siroter tranquillement sa tasse de café / thé matcha / jus d’épinards survitaminé (#IlEnfautPourToutLeMonde… 😉) tout en visualisant son tableau de bord sécurité quotidien contenant :
- Une liste des « signaux faibles » et nouveaux cas potentiels de shadow IT à investiguer afin de prévenir les attaques de sécurité et les risques de non-conformité.
- Un statut des actions automatiquement déclenchées à la suite à des comportements réseaux, systèmes ou applicatifs « anormaux » (et pré-validées, à la volée, par un référent SOC, bien sûr – on ne sait jamais…).
- Des propositions de mise à jour de travaux d’analyses de risques ou de classification de la sensibilité d’actifs, basées sur l’occurrence d’incidents cyber récents en interne ou chez d’autres acteurs dans son domaine d’activités
- Et !!!! last but not least, un résumé des dizaines et dizaines de newsletters reçues chaque jour, structuré autour de quelques thèmes clés de son choix.
Tout ceci peut sembler faire partie d’un avenir encore lointain… mais pas pour tout le monde ! Et en tout cas, pas si on s’attaque dès maintenant à l’ouvrage ! Ce qui est déjà le cas notamment pour Google, qui a lancé sa “AI Cyber Defense Initiative” pour faire en sorte que l’intelligence artificielle optimise les solutions de cyber sécurité. La pierre angulaire de cette initiative est Magika, un outil boosté à l’IA qui permet l’identification des types de fichiers jusqu’à détecter les logiciels malveillants et que Google utilise déjà dans plusieurs de ses produits. Selon Google, “Magika outperforms conventional file identification methods providing an overall 30% accuracy boost and up to 95% higher precision on traditionally hard to identify, but potentially problematic content such as VBA, JavaScript and Powershell”. De même, Google a prévu d’investir 2 millions de dollars en subventions et partenariats stratégiques pour soutenir la recherche dans plusieurs instituts, dont l’Université de Chicago, Carnegie Mellon et Stanford. L’entreprise a également annoncé la création d’un groupe cyber de 17 start-ups anglaises, américaines et européennes pour contribuer à renforcer l’écosystème transatlantique de la cybersécurité via des stratégies d’internationalisation, le développement d’outils d’IA et le renforcement les compétences nécessaires pour les utiliser.
L’objectif final de Google est de renverser le dilemme du défenseur, c’est à dire de faire en sorte que ce soit désormais le RSSI qui ait un coup d’avance et non plus le hacker… aaaah, le Saint Graal de la cyber…. Bon, Google reconnait lui-même qu’il y a encore “un peu “ de chemin à atteindre cet objectif, et que ça ne sera peut-être même qu’un vœu pieux. Mais qu’importe tant que cela soulève l’enthousiasme… et les budgets !
Quelles que soient les solutions sécurité boostées à l’IA qui émergeront dans les prochains mois ou années, l’objectif est que toutes ces améliorations permettent au RSSI de disposer de deux biens ultra précieux : du temps et des éléments factuels. Deux éléments qui lui permettront de se concentrer sur l’activité ayant la plus forte valeur ajoutée : ses échanges avec les métiers et le top management, où il sera en mesure de leur fournir des informations contextualisées sur l’impact de la sécurité sur l’ensemble des processus et actifs de l’entreprise et la meilleure manière d’aligner cette sécurité avec la stratégie de l’organisation.
On n’est pas loin du nirvana, non ?
Les enjeux
Alors soit… (non, il n’y a pas toujours un “mais”…. maaaaaais…. 😉).
Les enjeux à adresser pour atteindre ce paradis de la cyber AI restent de taille. On peut en citer plusieurs mais je voudrais me concentrer sur ceux propres à la gestion de la donnée. Car finalement, l’ “IA, it’s all about data !”.
Et dans ce domaine, les RSSI sont confrontés à une triple injonction :
- L’entrainement de modèles d’IA fiables et performants nécessite de collecter un grand volume de données de qualité. Sinon, on retombe vite sur le bon vieux classique « garbage in, garbage out ». Et plus les résultats produits par une IA sont utilisés pour prendre des décisions business, plus on a besoin qu’ils soient fiables, à un instant T mais aussi dans le temps. A la notion de qualité de la donnée, qui n’est pas nouveau dans le monde de l’IT. D’un point de vue cyber, on pense à la cartographie du SI, qualification des flux de données, classification des patterns de logs normaux / anormaux, etc… Des sujets vieux comme l’ISP… Or, nous savons tous qu’il s’agit d’un sujet critique encore mal maitrisé dans les organisations. D’autant plus qu’à l’enjeu de qualité vient s’ajouter celui de la capacité à collecter un grand volume. Qualité ET quantité.
Toutes les entreprises ont lancé des programmes de gestion de leurs données, métier, et techniques. On a vu arriver les architectures centralisées de type datawarehouse puis datalake, maintenant la tendance va à la décentralisation avec la philosophie du data mesh. Mais quel que soit le modèle choisi, la définition des propriétaires de la donnée, les responsabilités associées et le suivi de leur mise en œuvre dans le temps, la qualification des golden source, le stockage, l’archivage et la gestion des accès (…) restent des difficultés de taille pour toutes les organisations. Et l’arrivée de l’IA rend encore plus critique le besoin de trouver des solutions pérennes adaptées à la maturité, aux moyens, à l’historique technique et à la stratégie métier des organisations. CISO et CDO, le nouveau binôme de l’avenir pour un développement optimisé de l’IA, hors mais aussi dans le monde de la cyber ! - Et ce n’est pas fini ! Une fois qu’aura été traité le sujet de la maitrise des données en entrée, comment garantir que les résultats fournis sont et resteront suffisamment pertinents ? Sujet d’autant plus critique que plus on voudra que l’IA soit prédictive, plus il faudra accepter l’existence de périodes d’incertitude quant aux résultats produits. Incertitudes qui pourront avoir plusieurs origines (potentiellement cumulatives !) :
- Au début de son entraînement, difficile d’être sûr de la pertinence des résultats produits par un modèle, même si le processus d’entraînement est correctement effectué. Justement parce que nous ne saurons pas exactement à l’avance le.s résultat.s que nous serons en droit d’attendre ! C’est le principe même de l’IA prédictive
- De plus, à tout moment, le système d’IA peut être trompé et/ou attaqué, que ce soit par une action intentionnellement malveillante ou, plus simplement une erreur de configuration ou d’entraînement.
- Et enfin, rappelons-nous, il n’y a qu’une seule chose qui ne change pas, c’est le changement ! Les menaces évoluent sans cesse, les attaquants adaptent leurs techniques (et eux aussi peuvent s’appuyer sur l’IA !). Mais les environnements techniques et organisationnels des entreprises eux aussi se transforment en permanence. Dans ce contexte, les modèles des IA devront être ré-entrainés régulièrement. Et ces périodes cycliques d’ajustement devront être identifiées, déclenchées et maitrisées de façon très fine, sous peine de voir les IA devenir, au “mieux” obsolètes, au pire contre-productives.
- Et ultime sujet, si ce n’est le dernier : l’éthique ! Si la SSI souhaite manipuler de grandes quantités de données pour mieux assurer la sécurité des systèmes, comment s’assurer qu’elle ne deviendra pas alors le mauvais élève en termes de protection des données. Ça serait un comble, convenons-en ! Il conviendra donc d’anticiper pour encadrer les pratiques en termes d’accès, stockage, anonymisation et analyse des données pouvant être collectées, mais aussi d’actions automatisées pouvant être menées dans le cadre de processus d’enquêtes et de réaction… Je ne voudrais pas jeter le trouble, mais il serait peut-être utile d’envisager que le couple “CISO / CDO” évolue vers un mariage à trois avec le DPO ! 😊
Par conséquent, on voit bien que les enjeux de l’IA pour la cyber sécurité sont doubles. Il s’agit de pouvoir s’appuyer sur des solutions matures, mieux protéger des attaques malveillantes que nous avons évoqués dans la deuxième partie de cet article. Mais aussi, pour ne pas dire surtout, il va être nécessaire que les organisations gagnent elles-mêmes en maturité et se montrent capable de gérer les enjeux organisationnels et fonctionnels liés à l’intégration de résultats produits par l’IA dans leurs processus de décisions. Comme on l’a souvent vu dans les précédentes révolutions IT, la technique suivra, les outils deviendront de plus en plus robustes, performants, fiables… La technique est rarement, voire jamais, un enjeu indépassable. C’est tout un autre mur à franchir quand on parle de maturité des organisations et de capacité à gérer le changement, qui plus est de façon pérenne.
À ce titre, il me semble crucial que tout RSSI qui souhaite investir dans l’utilisation d’un système d’IA soit conscient, et informe clairement sa direction, le top management et les autres parties prenantes de l’entreprise, que le ROI dans les systèmes d’IA ne sera pas immédiat car ces solutions ne peuvent pas, du fait même de leur principe de fonctionnement, être opérationnelles rapidement et de façon immuable.
En corolaire, tous les bénéfices liés à l’automatisation des réponses basées sur les prédictions ou alertes de l’IA doivent être évalués avec beaucoup de circonspection. D’ailleurs, il suffit de se repenser aux incidents passés liés à ces pratiques pour s’en convaincre : rappelez-vous quand les premiers pare-feux et IDS/IPS “intelligents” sont apparus sur le marché. On nous promettait qu’ils seraient en mesure d’analyser à la volée les flux réseaux et d’enclencher automatiquement des règles de filtrage ou de redirection pour protéger nos SI en temps réels d’attaques externes ou internes. Des prises d’initiative ambitieuses… qui se sont souvent retournées contre les organisations, soient parce que les données en entrée n’étaient pas assez fiables pour garantir une réponse adaptée (tiens donc..) soit parce que les attaquants intégraient ces comportements prévisibles dans leurs propres scénarios d’attaque, en les retournant contre l’organisation elle-même.
Alors, on fait quoi ?
À ce stade, vous êtes en droit de me dire : “Heu… t’avais pas commencé ton article en nous parlant des bénéfices de l’IA pour la fonction SSI ? Si c’est ensuite pour nous brosser un portrait catastrophe de toutes les difficultés auxquels il faudra faire face pour cela… Merci du cadeau empoisonné ! ”
Aaaah, que nenni ! Je ne dis pas qu’il ne faut pas aller de l’avant. Il n’y a absolument aucun problème à défricher de nouveaux territoires, faire des innovations des opportunités et se jeter dans le vide de l’inconnu … en autant qu’on a un parachute bien attaché et qu’on s’est assuré de 2-3 heures de formation juste avant.
Alors, justement, quelles seraient les actions à mettre en œuvre dès maintenant pour faire de l’IA un nouvel élément de choix dans la boite à outil du RSSI ?
Je pourrais vous citer toute une série de pistes, mais j’ai choisi de me concentrer sur celles qui pour moi est la mère de toute : la formation, permettant la maitrise des concepts et technologies d’IA. C’est d’ailleurs ce à quoi, modestement, j’essaie de contribuer à travers cette série d’articles.
Selon moi, il est indispensable que les RSSI se forment dès à présent à la fois sur les mécanismes de l’IA et les technologies cyber qui les intègrent. Et à ce titre, je me permets un parallèle avec le domaine de l’informatique quantique. Je vois trop de responsables sécurité paniquer face au battage médiatique et marketing anxiogène autour de l’informatique quantique et de la possibilité de voir les algorithmes de chiffrement les plus utilisés se faire casser dans un avenir proche. Demain, l’année prochaine, dans moins de 5 ans au pire ! Tout simplement parce qu’ils ne connaissent pas les fondements techniques de l’informatique quantique, l’état réel de la recherche scientifique, ni l’ensemble des paramètres à prendre en compte (car non, ce n’est pas qu’une question de nombre de Qbit!). Ils sont donc à la merci des sirènes du marketing et des soi-disant experts des fournisseurs techniques prêts à leur vendre sans soucis des solutions à des problème qui n’existent pas encore !*
Loin de moi la volonté de jeter la pierre aux RSSI. Le domaine de la cyber sécurité est vaste, il évolue en permanence, et il est extrêmement compliqué de se tenir au fait de tous les sujets techniques, règlementaires, normatifs… Mais nous sommes déjà en train de voir toute une série de podcasts, conférences, webinars pour présenter de nouvelles solutions révolutionnaires de sécurité boostées à l’IA. Alors, oui, ces solutions ont sans doute beaucoup de valeur, et seront sans doute d’un apport significatif dans l’avenir, et il est donc important de commencer à s’y intéresser dès maintenant. Mais nous savons aussi toutes et tous que les promesses n’engagent que celles et ceux qui y croient et qu’entre ce qu’une solution peut faire sur le papier et va faire une fois installée dans un environnement…. il y a souvent comme un léger écart…. en général de la taille du pont de Brooklyn.
Par conséquent, il me semble crucial de mettre en place dès maintenant des actions de formation aux principes techniques de l’IA, aux lois, règlements et normes en vigueur et à venir, autant qu’une veille sur les outils actuellement ou bientôt disponibles sur le marché.
Au sein d’une grande équipe sécurité, il peut être opportun d’identifier au moins un collaborateur avec une appétence sur le sujet pour l’orienter vers un rôle de référent / futur champion de l’IA cyber. Pour tous les (trop) nombreux RSSI qui sont une équipes SSI à eux tout seul, commencez par potasser un ou deux livres de référence, demander une formation technique sur l’IA, assister à des conférences ou forums dédiés au sujet, subtilement suggérer aux référents d’associations professionnelles de mettre ce sujet au thème de leurs prochaines conférences. Et investissez aussi quelques heures à une veille “outillage”. Même si les fournisseurs de solutions peuvent vous jouer une sérénade exagérée, il est pertinent de commencer dès maintenant à vous intéresser aux promesses du marché, aux retours d’expérience concrets et à vous faire vos propres convictions sur le sujet.
* (d’ailleurs, je fais un pas de côté, mais si vous voulez en savoir plus sur les capacités actuelles de l’informatique quantique à mettre à mal les crypto-systèmes RSA et ECC, je vous conseille d’écouter cette vidéo, rediffusion d’une conférence de Jérémie Rodon sur ce sujet, et initialement présentée lors des GSdays 2023)
Nous voilà à la fin de cette série d’articles sur l’IA, son origine, les risques qui lui sont associés, les standards et lois qui encadrent son développement et son usage mais aussi les apports positifs à venir pour le monde de la cyber. J’espère modestement qu’il vous aura aidé à constituer le premier socle sur lequel continuer à poser vos connaissances et forger vos convictions en termes d’IA et de cyber. Comme toutes les précédentes innovations, l’IA n’est ni bien ni mal en soi. Et elle n’est pas non plus magique. Seuls les usages que nous déciderons d’en faire, ou que nous laisserons les autres en faire, fera pencher la balance vers plus d’avantages ou de désavantages. Alors soyons informés, préparés et vigilants pour aller de l’avant avec les bons outils et la bonne cible, sans confiance naïve mais sans méfiance contre-productive non plus. Un chemin à construire avec toutes les parties prenantes de l’organisation, le monde scientifique, les représentants étatiques, les fournisseurs technologiques et, last but not least, les utilisateurs finaux !
Bibliographie
- Les États-Unis veulent contrecarrer les risques liés à l’IA
- Conférence de Dartmouth
- Google dévoile le 1er robot capable de s’améliorer seul : la prochaine étape de l’IA ?
- Le Petit Illustré Intelligence Artificielle Regards croisés de chercheur·es
- MLOps
- Apprentissage supervisé
- Apprentissage non-supervisé
- Apprentissage semi-supervisé
- Intelligence Artificielle générative
- Grand modèle de langage
- Unlocking Europe’s AI potential in the digital decade
- Explorons l’avenir de l’intelligence artificielle : Progrès, possibilités et implications
- Statistiques sur l’intelligence artificielle que vous devez connaître en 2024 – Qui l’utilise & Comment ?
- A Patchwork Of US AI Regulations Is Here — It’s Time To Deal With It
- House launches bipartisan task force on articifial intelligence
- Législation sur l’intelligence artificielle
- AI Security Overview
- How to attack Machine Learning (Evasion, Poisoning, Inference, Trojans, Backdoors)
- Securing generative AI: An introduction to the Generative AI Security Scoping Matrix
- Dossier Sécurité des systèmes d’IA du Laboratoire d’Innovation Numérique de la CNIL
- State of AI in the cloud 2024
- The OWASP AI Exchange: an open-source cybersecurity guide to AI components
- Les systèmes d’IA font face à des menaces croissantes : le NIST a identifié les différents types de cyberattaques qui manipulent le comportement des systèmes d’IA
- AMRAE – Panorama 2023 de la gestion des risques : les SIGR sont plébiscités par le monde de la gestion des risques
- Gen AI-fueled cyberattacks pushed remediation costs in 2023
- Avec le reporting ESG en ligne de mire, les entreprises digitalisent leur gestion des risques
- Avec l’AI Act, la gouvernance des données est le chantier prioritaire
- Report: World governments must act to create generative AI safeguards
- Top 4 LLM threats to the enterprise
- AI algorithms: harnessing Machine Laerning with MLOps
- Allianz Risk Barometer – Identifying the major business risks for 2024
- Assessing and quantifying AI risk; A challenge for entreprises
- Modèle open source ou propriétaire : quelle stratégie d’IA adopter pour ses projets ?
- IA responsable : cinq façons pour les banques de s’y mettre
- Google launches a slew of AI initiatives to enhance cybersecurity
- Pour Yann LeCun, l’IA générative est une impasse
- 4 bonnes raisons de miser sur l’IA pour votre sensibilisation
- A quoi s’attendre en matière de cybersécurité en 2024
- GDPR Compliance in the Age of Artificial Intelligence
- A changing world requires CISOs to rethink cyber preparedness
- L’IA dans les entreprises françaises : 1 explosion, 2 freins
- A year after ChatGPT’s debut, is GenAI a boom or the bane of the CISO’s existence?
- The Future of CISO: From Technical Expert to Business Leaders
- Baromètre de la cybersécurité, d’opinionway pour CESIN
- Maintenant que Giskard est éprouvé auprès des clients français, il s’agit de lui donner une ampleur mondiale


